Section author: Rebecca Vederhus, Sebastian Jentschke
எச்.பி.எச்.எச் முதல் சாமோவி வரை: கோவாரன்ச் பகுப்பாய்வு (அன்கோவா)
SPSS மற்றும் சாமோவியில் ஒரு முன்கணிப்பு மற்றும் இரண்டு போலி மாறிகள் கொண்ட பின்னடைவு எவ்வாறு செய்யப்படுகிறது என்பதை இந்த ஒப்பீடு காட்டுகிறது. SPSS சோதனை `புலம் (2017) <https://edge.sagepub.com/field5e> __, குறிப்பாக வெளியீடு 13.1 - 13.2 இன் அத்தியாயம் 13.3 இல் உள்ள விளக்கத்தைப் பின்பற்றுகிறது. இது தரவுத் தொகுப்பைப் பயன்படுத்துகிறது ** நாய்க்குட்டி காதல் dumm.sav **, இது <https://edge.sagepub.com/field5e/student-resources/datasets> ____.
SPSS |
jamovi |
|---|---|
SPSS இல் நீங்கள் ஒரு பின்னடைவைப் பயன்படுத்தி இயக்கலாம்: `` பகுப்பாய்வு` → `` பின்னடைவு`` → `` நேரியல்``. |
சாமோவியில் நீங்கள் இதைப் பயன்படுத்தி இதைச் செய்கிறீர்கள்: `` அனலீச்` `` பின்னடைவு`` நேரியல் பின்னடைவு`. |
|
|
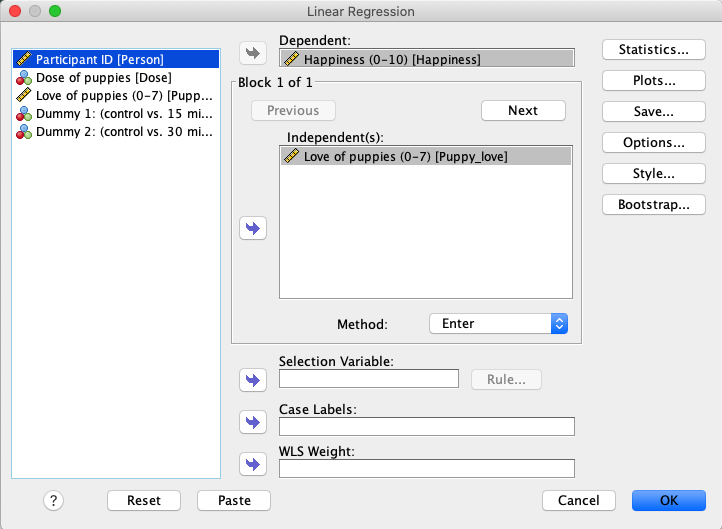
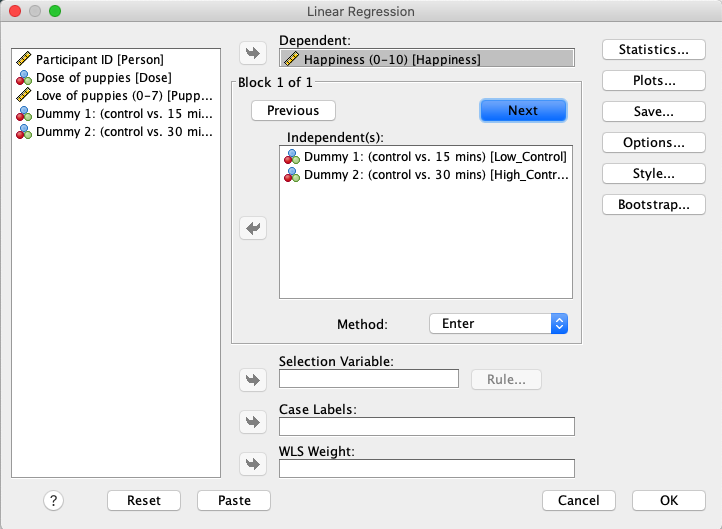
SPSS இல், `` மகிழ்ச்சியை`` மாறி பெட்டியில் `` சார்பு`` மற்றும் `` Puppy_love`` க்கு மாறி பெட்டியின் `` சுயாதீன (கள்) `` க்கு நகர்த்தவும். |
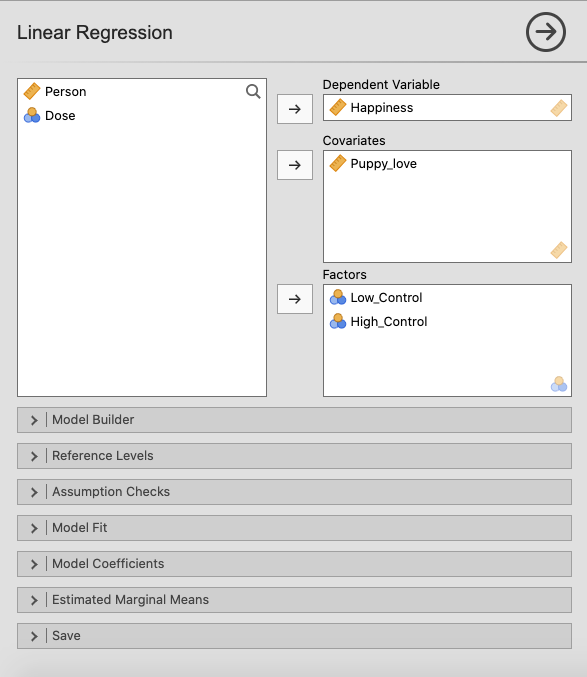
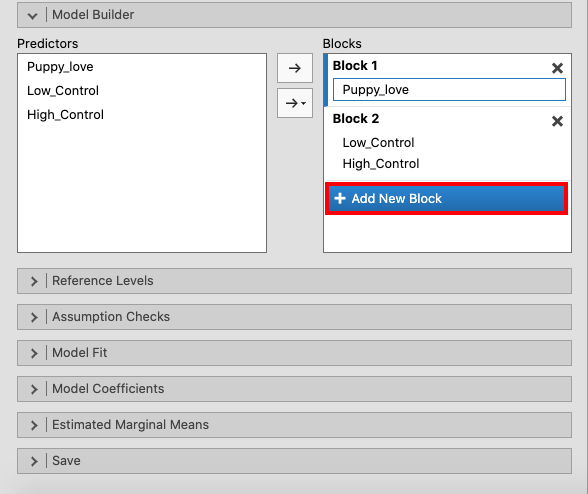
சாமோவியில், `` மகிழ்ச்சியை`` மாறி பெட்டியில் `` சார்பு மாறி``, `` பப்பி_லோவ்`` ஆகியவற்றை மாறி பெட்டியின் `` கோவாரியட்டுகள்``, மற்றும் `` லோ_ கன்ட்ரோல்` மற்றும் `` ஐ_ கன்ட்ரோல்`` க்கு நகர்த்தவும் காரணிகள் பெட்டி. |
|
|
`` சுயாதீன (கள்) `` `` `` `` அடுத்த`` பொத்தானை அழுத்தி, `` லோ_ கன்ட்ரோல்`` மற்றும் `` ஐ_கான்ட்ரோல்` ஆகியவற்றை இந்த பெட்டியில் நகர்த்தவும். |
`` மாதிரி பில்டர்`` ஐப் பயன்படுத்தி சுயாதீன மாறிகளின் புதிய தொகுதியை உருவாக்கவும். |
|
|
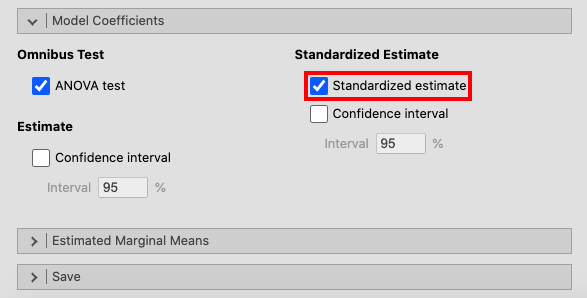
`` மாதிரி குணகங்கள்`` சாளரத்தைத் திறந்து, `` தரப்படுத்தப்பட்ட மதிப்பீட்டிற்கு` `` `` தரப்படுத்தப்பட்ட மதிப்பீட்டைத் தட்டவும். |
|
|
|
நீங்கள் SPSS மற்றும் JAMOVI வெளியீடுகளை ஒப்பிட்டுப் பார்த்தால், முடிவுகள் ஒன்றே. இருப்பினும், சமோவியிலிருந்து வெளியீடு மிகவும் தெளிவாக உள்ளது, ஏனெனில் இது மிக முக்கியமான தகவல்களை மட்டுமே உள்ளடக்கியது. முடிவுகள் SPSS மற்றும் சாமோவியில் சற்று வித்தியாசமான இடங்களில் காணப்படுகின்றன. |
|
|
|
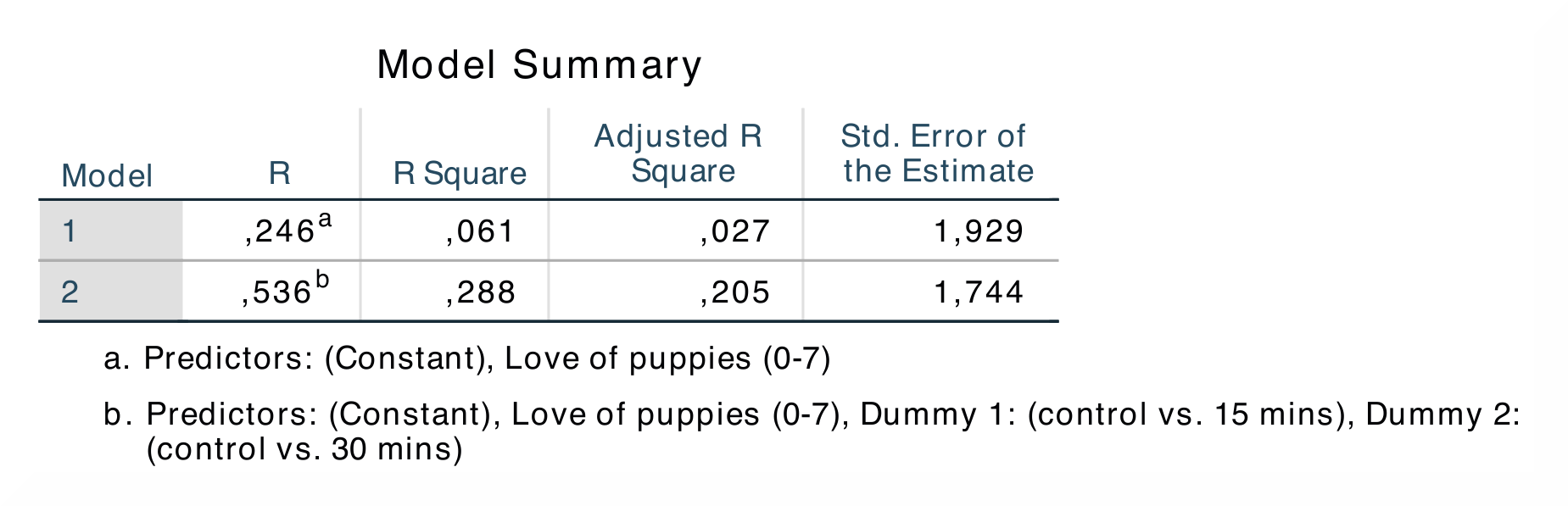
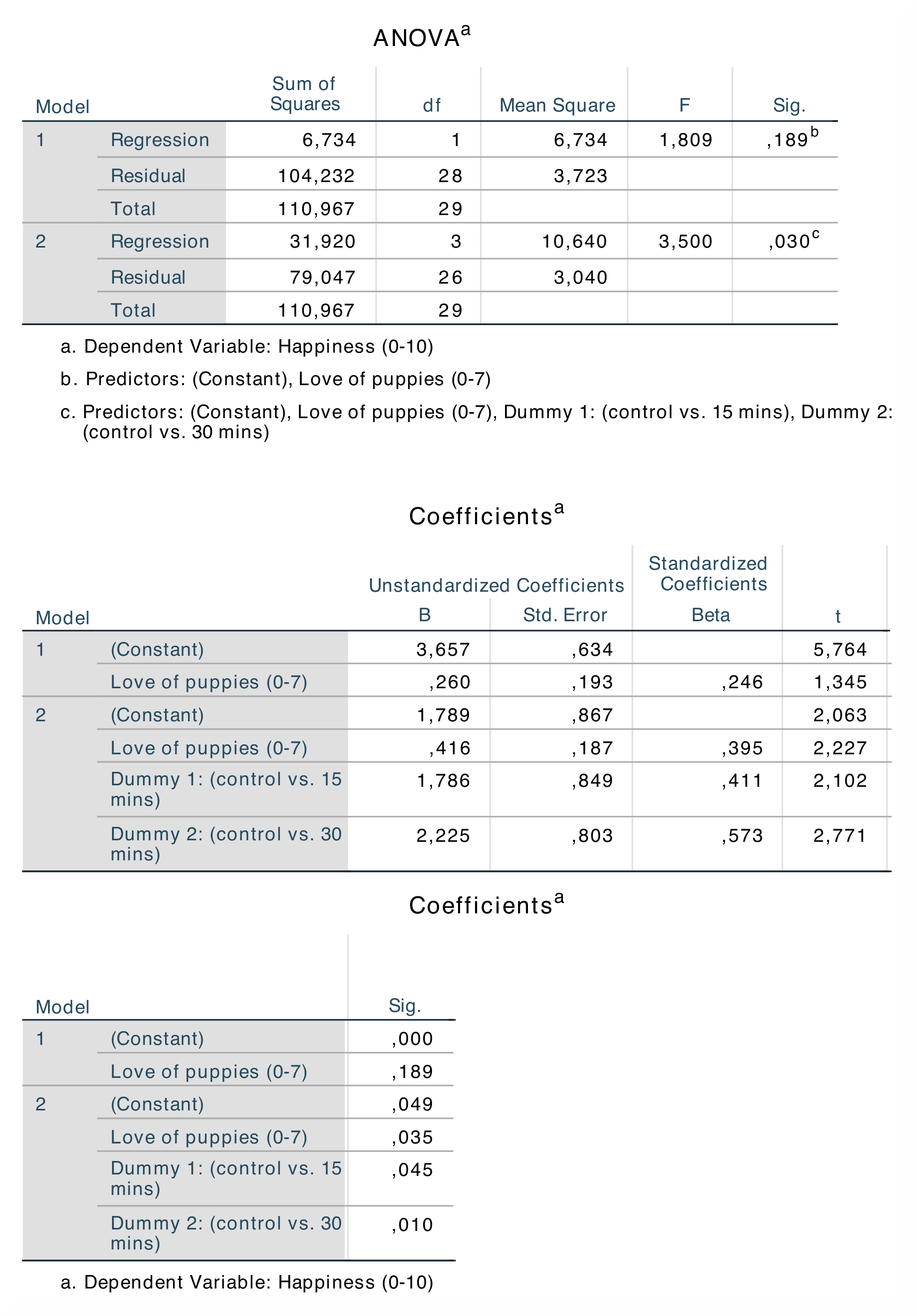
SPSS இல், வெளியீட்டு அட்டவணை `` மாதிரி சுருக்கம்`` *r *மற்றும் *r² *உடன் தொடங்குகிறது. மாதிரி 1 க்கான *r² *-மதிப்பு பகுப்பாய்வில் கோவாரியேட் மட்டுமே சேர்க்கப்படும்போது பொருத்தத்தின் நன்மையைக் காட்டுகிறது, மேலும் மாதிரி 2 க்கான மதிப்பு போலி மாறிகள் மற்றும் கோவாரியேட் சேர்க்கப்படும்போது முடிவுகளைக் காட்டுகிறது. `` அனோவா`` அட்டவணை பின்னடைவுக்கான சதுரங்களின் தொகையை முன்வைக்கிறது, இது மாதிரி எத்தனை யூனிட் மாறுபாட்டைக் கணக்கிடுகிறது என்பதை நமக்குக் கூறுகிறது. மிகவும் சுவையான அட்டவணை `` குணகங்கள்` அட்டவணை, அங்கு நீங்கள் *B- *மதிப்புகள் மற்றும் இரண்டு மாதிரிகளுக்கான *β *மதிப்புகள் மற்றும் அவற்றின் முக்கியத்துவ மதிப்புகளில் உள்ள வேறுபாடுகளைக் காணலாம். |
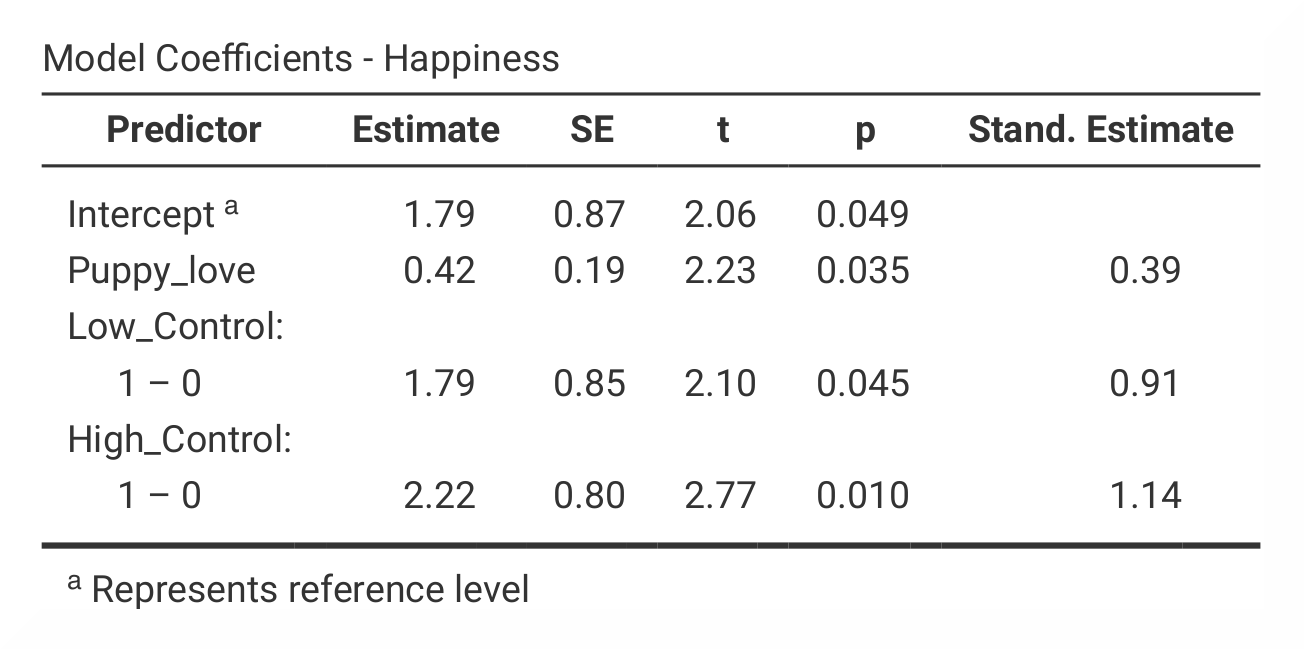
சாமோவியில், *r *மற்றும் *r² *-மதிப்புகள் வெளியீட்டு அட்டவணையில் `` மாதிரி பொருத்தம் நடவடிக்கைகள்`` இல் காணப்படுகின்றன. சதுரங்கள் மற்றும் *f *-மதிப்புகள் `` ஆம்னிபச் அனோவா டெச்ட்`` அட்டவணையில் காணப்படுகின்றன, இது சாமோவியில் மாதிரி 1 க்கான அட்டவணையாகவும், மாடலுக்கான அட்டவணையாகவும் பிரிக்கப்பட்டுள்ளது. ஆயினும்கூட, எண்கள் ஒரே இடத்தில் தோன்றும் அட்டவணையில். `` குணகங்கள்` அட்டவணை இரண்டு அட்டவணைகளாக பிரிக்கப்பட்டுள்ளது - ஒவ்வொரு மாதிரிக்கும் ஒன்று - சாமோவியில். இங்கே *பி *-மதிப்புகள் மதிப்பீட்டின் கீழ் காணப்படுகின்றன மற்றும் *β *-மதிப்புகள் நிலைப்பாட்டின் கீழ் உள்ளன. மதிப்பீடு. |
*R *மற்றும் *r² *-மதிப்புகள் முதல் மற்றும் இரண்டாவது நெடுவரிசையில் முதல் வெளியீட்டு அட்டவணையில் SPSS மற்றும் JAMOVI இரண்டிலும் காணப்படுகின்றன. SPSS க்கு மாறாக, மாதிரி 1 மற்றும் மாதிரி 2 க்காக `` ANOVA`` மற்றும் `` குணகங்கள்`` ஐ சாமோவி பிரிக்கிறது. இது இருந்தபோதிலும், கிட்டத்தட்ட எல்லா மதிப்புகளும் ஒரே நெடுவரிசைகளில் காணப்படுகின்றன, அவை *β *-மதிப்புகள் தவிர, இது SPSS இல் *t *- மற்றும் *P *-மதிப்புகள் மற்றும் சமோவியில் *t *- மற்றும் *p *-மதிப்புகளுக்குப் பிறகு அமைந்துள்ளது. மாதிரி 2 புள்ளிவிவரங்களுக்கான எண் மதிப்புகள் ஒரே மாதிரியானவை: * r * = 0.54, * r² * = 0.29; * பி* = 0.42,* ப* <.05; * β* = 0.39,* ப* <.05. |
|
தொடரியல் பயன்படுத்தி அந்த பகுப்பாய்வுகளை நீங்கள் பிரதிபலிக்க விரும்பினால், நீங்கள் கீழே உள்ள கட்டளைகளைப் பயன்படுத்தலாம் (சாமோவியில், கீழே உள்ள குறியீட்டிற்கு நகலெடுக்கவும் Rj). மாற்றாக, நீங்கள் SPSS வெளியீட்டு கோப்புகள் மற்றும் சாமோவி கோப்புகளை தொடரியல் கீழே இருந்து பகுப்பாய்வுகளுடன் பதிவிறக்கம் செய்யலாம். |
|
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Happiness
/METHOD=ENTER Puppy_love
/METHOD=ENTER Low_Control High_Control.
|
jmv::linReg(
data = data,
dep = Happiness,
covs = Puppy_love,
factors = vars(Low_Control, High_Control),
blocks = list(
list("Puppy_love"),
list("Low_Control", "High_Control")),
refLevels = list(
list(var="Low_Control", ref="0"),
list(var="High_Control", ref="0")),
anova = TRUE)
|