この節の作者: Jonathon Love
jamoviとRの連携
jamoviの大きな利点は、R統計言語の上に構築されているだけでなく、jamoviからRへ、またRからjamoviへ非常に簡単にアクセスできる点です。シンタックスモード、 Rj 、 jmvconnect 、 jmvReadWrite がその実現を助けてくれます。
シンタックスモード
jamovi には「R シンタックスモード」が用意されており、このモードでは各分析に対応する R コードが自動的に生成されます。シンタックスモードに切り替えるには、jamovi 画面右上のアプリケーションメニュー(縦に三つ並んだ点「⋮」)をクリックし、表示される
シンタックスモードチェックボックスにチェックを入れてください。もう一度クリックするとシンタックスモードを解除できます。シンタックスモードでは、分析はこれまで通り実行されますが、Rの構文(Rシンタックス)が生成されます。jamoviのすべての結果オブジェクトと同様に、これらの項目(Rシンタックスも含めて)は右クリックしてコピーし、たとえばRのセッションに貼り付けることもできます。jamoviに含まれているすべての分析は、Rパッケージ jmv を使うことでRセッション内でも利用できます。
生成されるRの構文(Rシンタックス)にはデータのインポート手順は含まれていませんが、これはRパッケージ
jmvconnectとjmvReadWriteを使うことで簡単に実現できます(詳細は後述)。jmvReadWriteはRでjamoviのデータファイル(.omv)の読み書きを可能にし、jmvconnectはjamoviセッションで開いているデータセットにRからアクセスできるようにします。
Rj エディタ
Rjエディタを使うと、jamovi内で直接Rのコードを用いてデータを分析したり、お気に入りのRパッケージをjamoviから利用したりできます。Rjはjamoviのモジュールの一つで(インストール方法については Install modules in jamovi 参照)jamovi内でRプログラミング言語を使ってデータ分析を行えるようにします。
これを行いたい理由はさまざまです。Rパッケージには、まだjamoviのモジュールとして提供されていない多くの分析手法があり、
Rjを使うことで、そうした分析をjamovi内から利用できるようになるというのはその1つです。さらに、ループやif文なども利用できるため、条件付きの分析やシミュレーション研究など、より柔軟な処理が可能になります。人によっては、スプレッドシート上でRを使うことが、
Rの学習を始める最適な方法となるでしょう。また、技術的なことにあまり詳しくない同僚(中には単純にコーディングが好きな人もいるでしょうが)と簡単に共有する手段にもなります。Rによる分析を実行するには、
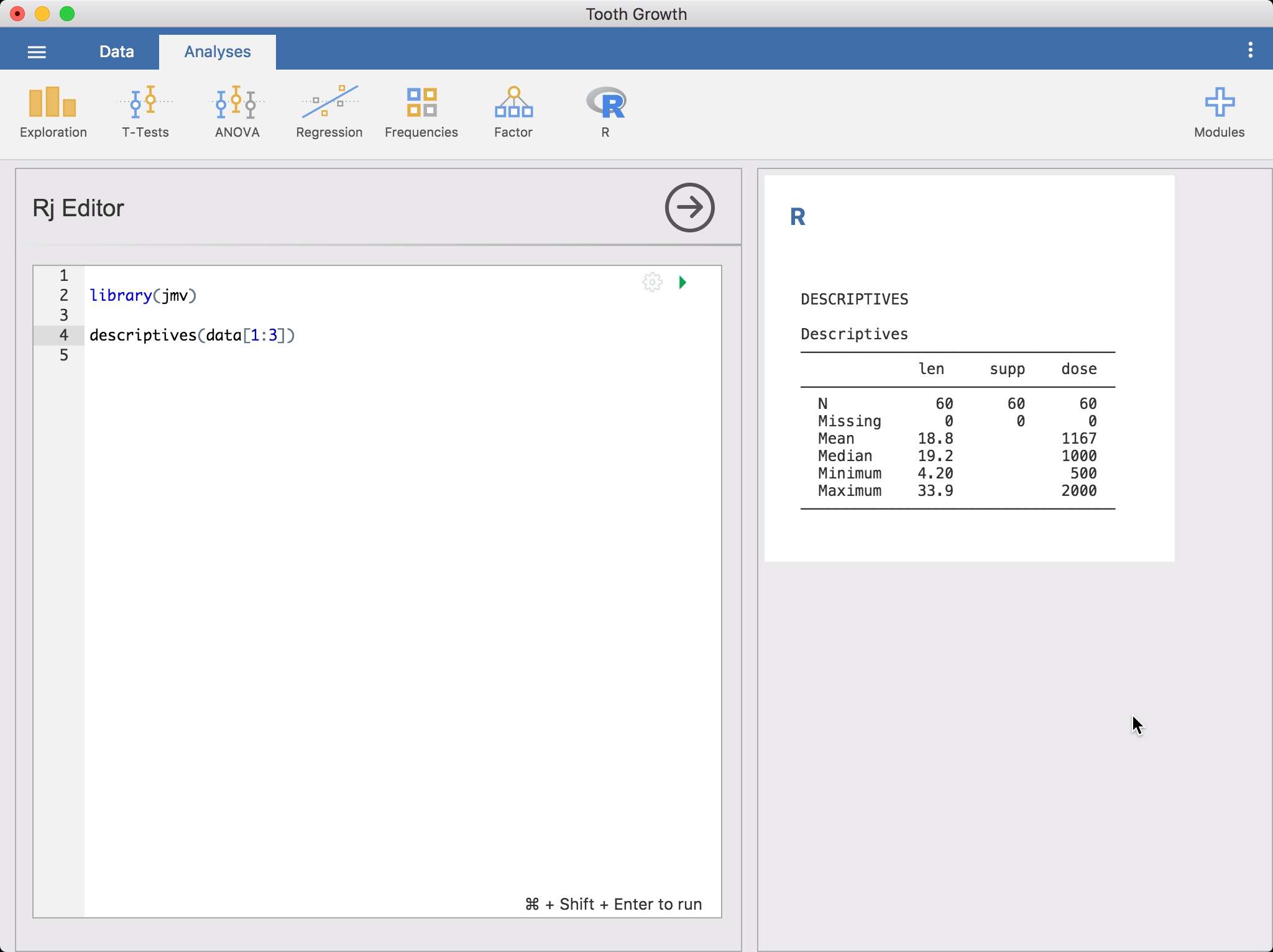
分析(Analyses)リボンのRアイコンからRj Editorを選択します。これにより、Rコードを入力するためのエディタが表示されます。jamoviで開いているデータセットは、単にdataという名前のデータフレームとして利用できます。まずは、記述統計(descriptives)を実行してみるとよいでしょう。
もし、
dplyr流のやり方が好きなら、次のように書くこともできます。library(jmv) library(dplyr) library(magrittr) select(data, 1:3) %>% descriptives()コードを入力しているとき、 Rj が自動的に関数名を提案してくれることに気づくでしょう。コードを実行するには、緑色の三角ボタンをクリックするか、Control + Shift + Enter(Macの場合は ⌘ + Shift + Enter)を押します。すると、jamoviは
Rのコードを実行し、その結果が他の分析と同じように結果パネルに表示されます。コードに変更を加えて、再度実行することも可能です。初期設定では、
Rjはjamoviに同梱されているRのバージョンを利用します。このバージョンには多くのパッケージ(jmvおよびその依存パッケージ)が含まれており、多くのユーザーにとってはこれで十分でしょう。追加のRパッケージを使いたい場合はSystem Rバージョンを利用してください。コードボックス右上の歯車アイコン(⚙)を選択すると、使用するRのバージョンを変更するオプションが表示されます。System Rでは、システムにインストールされているRのバージョンを利用します。これにより、そのRバージョンにインストールされているすべてのパッケージにアクセスできるという利点があります。必要なのは 、jmvconnectRパッケージをシステムのRライブラリにインストールしておくことだけです。

jmvconnect Rパッケージ
jmvconnectRパッケージは、システム上のRからjamoviで開いているデータセットにアクセスできるようにします。Rで次のようにしてインストールしてください。install.packages('jmvconnect')これが完了すれば、
jamovi RからSystem Rにスムーズに移行できるはずです。
System Rを利用する場合、jamoviファイルを同僚と共有する際には少し複雑になることに留意してください。同僚があなたの分析を修正したり再実行したりしたい場合、同じRパッケージがインストールされている必要があります。これは柔軟性の代償です!初期設定では、
RjがRコードを実行する際、データセット全体をdataという名前のデータフレームとして利用します。しかし、実際の分析では、必要な列はごく一部であり、全データセットを使う必要がない場合も多いでしょう。スクリプトの先頭に特別なコメントを追加することで、分析で利用可能な列を制限することもできます。そのコメントの形式は次の通りです。# (column1, column2, column3) library(jmv) ...この場合、指定した列だけが data データフレームに表示されます。とくに大規模なデータセットを扱う場合、これによって分析の処理速度が向上します。さらに、jamoviは分析でこれらの列だけが使われていると認識するため、他の列に変更が加えられても分析を再実行する必要がなくなります。
データセットの分析をRセッションに移行したいと思うことがあるかもしれません。こうした場合に便利なのが
jmvconnectRパッケージです。jmvconnectを使うと、実行中のjamoviからRセッションにデータセットを読み込むことができます。このパッケージには2つの関数があり、what()は利用可能なデータセットを一覧表示し、read()はそれらを読み込みます。たとえば、次のように使うことができます。> library(jmvconnect) > what() Available Data Sets ───────────────────────────────────── Title Rows Cols ───────────────────────────────────── 1 iris 150 5 2 Tooth Growth 60 3 ─────────────────────────────────────そして、次のいずれかのコマンドでデータセットを読み込むことができます。
data <- read('Tooth Growth') data <- read(2)
jmvReadWrite Rパッケージ
jmvReadWriteRパッケージは、Rでjamoviデータファイル(.omv)の読み書きを行います。これは、次のようにしてインストールします。install.packages('jmvReadWrite')典型的な使い方としては、たとえば実験の複数の参加者から得られたCSVファイルや、異なる質問票からの回答データなど、多数の結果ファイルを処理したい場合が挙げられます。データの整形やクリーニングといったラングリング(wrangling)は、Rで行ったほうが簡単な場合もよくあります。それらのファイルからデータセットをまとめたら、
write_omv()関数を使って書き出すことができます。library(jmvReadWrite) # assemble your data set (named dtaSet)... write_omv(dtaSet, "FILENAME.omv")同様に、
read_omv関数を使うことで、jamoviデータファイルをRに読み込むことができます。もう一つの典型的な使い方としては、データファイルを読み込み、現在jamoviではできない操作をRで行い、その結果を修正したファイルとして(jamoviファイル形式で)書き戻す、というものがあります。library(jmvReadWrite) dtaSet <- read_omv("FILENAME.omv") # do some modifications to your data set write_omv(dtaSet, "FILENAME.omv")
jmvReadWriteにはいくつかの補助関数が実装されています。これらを使うことで、データセットの列や変数の並び替え(arrange_cols_omv)、複数のデータファイル(たとえば以前使っていた統計ソフトのデータ)を一括してjamoviファイル形式に変換する(convert_to_omv)、データファイルのロング形式からワイド形式への変換(long2wide_omv)、ワイド形式からロング形式への変換(wide2long_omv)、複数のデータセットの変数を結合する(merge_cols_omv)、複数のデータセットでケースを結合する(merge_rows_omv)、1つまたは複数の変数でデータセットを並べ替える(sort_omv)といった操作が可能です。
read_omvのもう一つの利用例として、jamoviでの分析結果を使ってR Markdownファイルを作成することが挙げられます。getSynパラメータは、ファイル内に含まれる分析のシンタックス(構文)を抽出するかどうかを指定します。シンタックスを実行するには、jmvRパッケージがインストールされている必要があります。あとで結果を扱いたい場合は、それらを変数に代入しておくことをおすすめします(下記の2つ目のevalを参照)。結果の表は、asDF関数を使って(たとえばresult$main$asDFのように使うことで)データフレームに変換できます。library(jmvReadWrite) library(jmv) data <- read_omv("FILENAME.omv", getSyn = TRUE) # the analyses are stored in the attribute syntax attr(data, "syntax") # with using an index, the n-th analysis can be accessed (first line) # and run / evaluated (second line) attr(data, "syntax")[[1]] eval(parse(text = attr(data, "syntax")[[1]])) # often it is more useful to assign the results to a variable when # running analyses and later on use the contents of that variable eval(parse(text = paste0("result = ", attr(data, "syntax")[[2]]))) names(result) # (returns the names of the output elements - tables, figures, and # groups: sub-headings, e.g., Estimated Marginal Means in an ANOVA, # that contain further tables and figures)