この節の作者: Jonathon Love
スプレッドシート
jamoviでは、データはスプレッドシートで表現されており、各列が「変数」を表しています。
データ変数
jamoviで最も一般的に使われる変数は「データ変数」です。この変数は、データファイルから読み込んだデータや、ユーザーが直接入力したデータです。データ変数は、次の3つのデータ型のいずれかになります。
整数
小数
文字また、測定値型は次の4つです。

Nominal

Ordinal

Continuous

ID各変数列のヘッダーには、測定値型が記号で示されます。なお、データ型と測定値型の組み合わせによっては意味をなさないものもあり、jamoviではそのような組み合わせは選択できません。
名義と順序は、その名の通り名義尺度変数や順序尺度変数に使われます。連続は、数値データで間隔尺度や比率尺度とみなされる変数に使われます(SPSSのスケールと同等です)。ID型は、他とは異なりjamovi独自のものです。これは、分析対象としない識別子(例:氏名や参加者IDなど)を含む変数に使われます。ID型の利点は、jamoviが内部で水準(レベル)リストを保持する必要がなくなるため、非常に大きなデータセットを扱う際のパフォーマンスが向上することです。空白のスプレッドシートから値を入力し始めると、入力したデータの内容に応じてデータ型や測定値型が自動的に切り替わります。これは、どの変数型がどのようなデータに対応しているかを理解するのによい方法です。同様に、データファイルを開いた場合も、jamoviは各列のデータから変数型を推測します。いずれの場合も、これらの自動判定が必ずしも正しいとは限りません。その場合は、変数エディタを使ってデータ型や測定値型を手動で指定する必要があります。
変数エディタは、
データ(Data)タブの設定(Setup)を選択するか、列ヘッダーをダブルクリックするか、F3キーを押すことで起動できます。変数エディタでは、変数名の変更や(データ変数の場合は)データ型、測定値型、水準の順序、各水準に表示されるラベルの変更が可能です。変数エディタは、閉じる矢印をクリックするか、再度F3キーを押すことで閉じることができます。新しい変数は、データリボンの
追加(Add)ボタンを使ってデータセットに挿入したり追加したりできます。追加ボタンからは 計算変数 を追加することもできます。
計算変数
計算変数は、他の変数に対して計算を行うことで値が決まる変数のことです。計算変数は、対数変換、zスコア、合計スコア、逆点化、平均値の算出など、さまざまな目的で利用できます。
データタブにある
追加(Add)ボタンを使うことで、 計算変数 をデータセットに追加できます。これをクリックすると、数式を指定するための数式ボックスが表示されます。ここでは通常の算術演算子が利用可能です。数式は次のように使用します。A + B LOG10(len) MEAN(A, B) (dose - VMEAN(dose)) / VSTDEV(dose) Z(dose)これらは順に、AとBの合計、
lenの常用対数変換、AとBの平均、そしてdoseのzスコア(2とおりの計算方法)です。これ以外にもたくさんの関数が利用可能です。
V 関数
いくつかの関数はペアになっており、一方には
Vが頭につき、もう一方にはつきません。V付きの関数は、変数全体に対して計算を行い、Vなしの関数は行ごとに計算を行います。たとえば、MEAN(A, B)は各行ごとにAとBの平均を計算しますが、VMEAN(A)はA全体の値の平均を返します。さらに、
V関数はgroup_by引数をサポートしています。group_by変数を指定すると、その変数の各水準ごとに個別の値が計算されます。次の例を見てください。VMEAN(len, group_by=dose)この例では、
doseの各水準ごとに個別の平均値が計算され、計算変数の各値は、その行のdoseの値に対応する平均値となります。
変換(再コード化)変数
計算変数は、合計スコアの計算やデータ生成など、多くの操作にとても便利です。しかし、複数の変数をコード化し直したり変換したりしたい場合(たとえば、アンケートのデータセットで複数の回答を逆点化する場合など)には、やや面倒になることがあります。「変換変数」を使うと、既存の変数を簡単にコード化し直したり、多くの変数に一度に変換を適用したりできます。
変換変数の作成
jamoviで変数の変換や再コード化を行うと、元の「変換元の変数」に対して2つ目の「変換変数」が作成されます。このため、元の未変換データには必要に応じてつねにアクセスできます。変数を変換するには、まず変換したい列を選択します。列のブロックを選択する場合は、ブロック内の最初の列ヘッダーをクリックし、Shiftキーを押しながら最後の列ヘッダーをクリックします。あるいは、Ctrlキー(Macの場合はCmdキー)を押しながら列ヘッダーをクリックすることで、個別に列を選択・解除することもできます。選択ができたら、データタブから
変換(Transform)を選択するか、右クリックしてメニューから変換(Transform)を選びます。選択した変数のいずれかを右クリックし、
変換(Transform)をクリックします。
あるいは
データ(Data )リボンの変換(Transform)をクリックします。
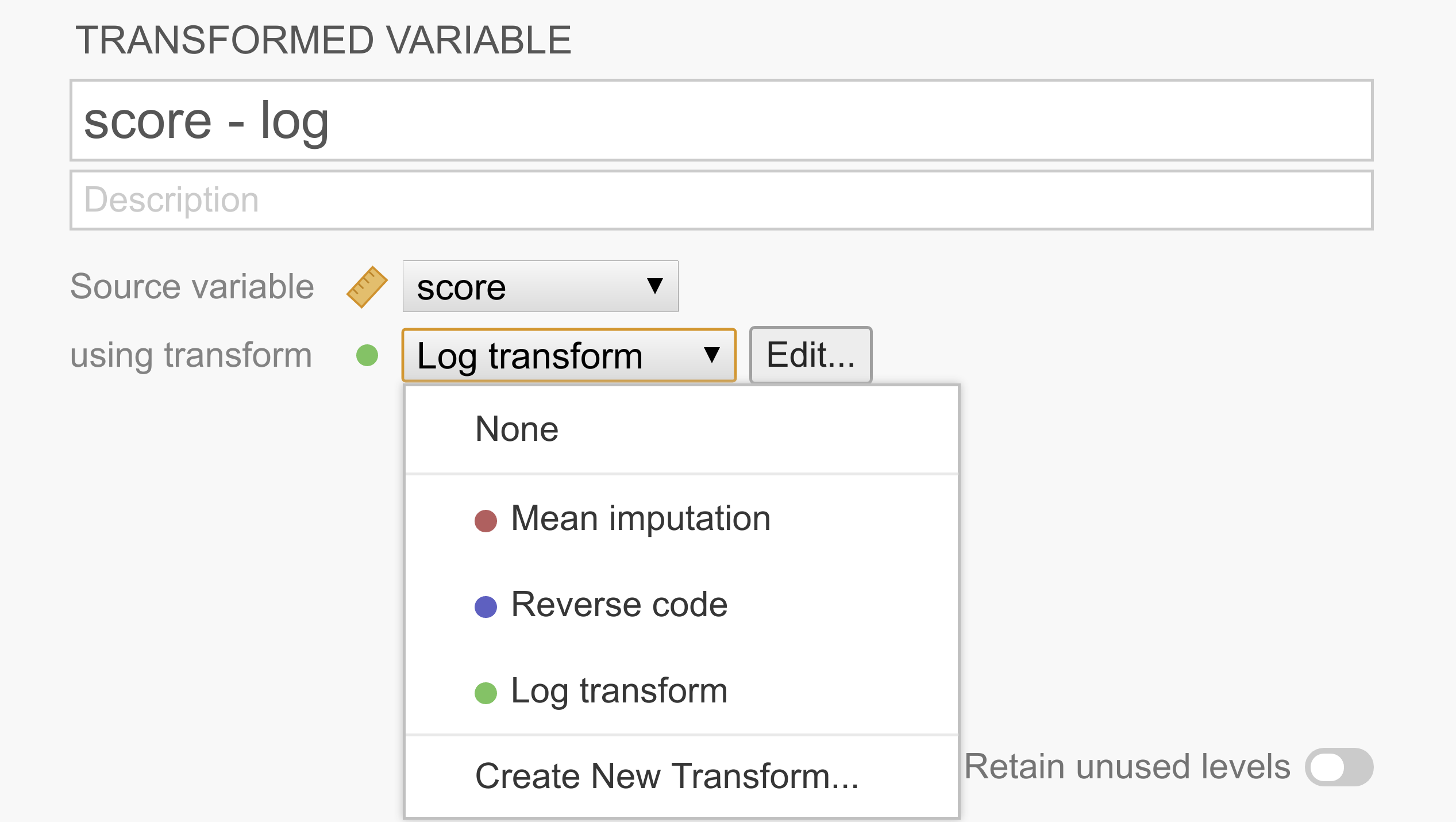
これにより、選択した各列に対して2つ目の「変換変数」が作成されます。次の例では、変数を1つだけ選択したため、1つの変数(score - log)の変換だけ設定していますが、一度に複数の変数を変換することも可能です。
上の図に示されているように、各変換変数には「変換元の変数」があり、これは元の未変換の変数を表しています。また、「変換」は、変換元の変数を変換変数に変換するためのルールを表します。一度変換を作成すると、その変換はリストに保存され、複数の変換変数間で簡単に共有できます。
まだ適切な変換が定義されていない場合は、リストから
変換を新規作成...(Create new transform...)を選択できます。変換の新規作成
変換を新規作成...をクリックすると、変換エディタが画面にスライド表示されます。
変換エディタには、これらの要素が含まれています。
変換名 :変換の名前。
説明 (Description):変換の内容が分かるように、あなた自身や他の人のために説明を記入するスペースです。
変数の接尾辞 (Variable suffix)(省略可):ここでは、変換変数のデフォルトの命名形式を定義できます。デフォルトでは、変数接尾辞が変換元変数名の後ろにダッシュ(-)で区切って付加されます。しかし、三点リーダ(...)を使うことでこの動作を上書きできます。たとえば、Q1という変数を変換する場合、変数接尾辞を使って次のような命名規則を適用できます(空欄のままにすると、変換名が変数の接尾辞として使われます)。
log→Q1 - log..._log→Q1_loglog(...)→log(Q1)変換 :このセクションには、変換のためのルールや数式を記述します。計算変数で利用できるすべての関数を使うことができ、元の列の値を参照して変換を行う場合は、特別な
$sourceキーワードを使います。変数を複数のグループに再コード化したい場合は、複数の条件を使うのが最も簡単です。追加の条件(つまりif文)を追加するには、変換条件を追加(Add recode condition)ボタンをクリックします。使用中 (Used by):この特定の変換を使用している変数の数を示します。数字をクリックすると、それらの変数が一覧表示されます。
測定値型 (Measure type):初期設定では、測定値型は「自動」に設定されており、変換内容から自動的に測定値型が推定されます。しかし、自動で正しく測定値型が推定されない場合は、ここで手動で上書きできます。
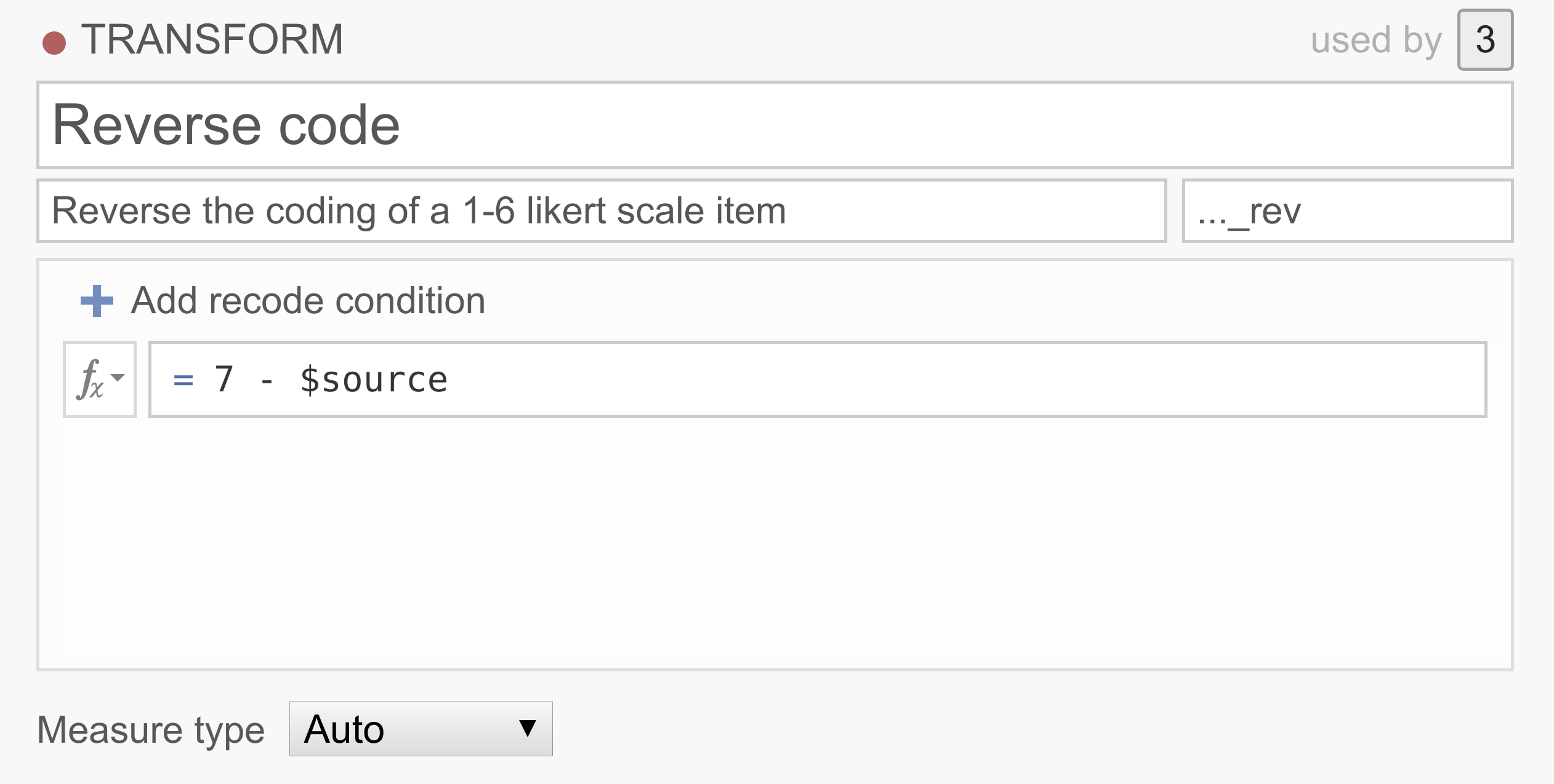
例1:逆転項目の処理
アンケートデータには、分析前に値を逆転させる必要のある項目が1つ以上含まれていることがよくあります。たとえば、「私はパーティーに行くのが好きだ」、「人と一緒にいるのが大好きだ」、「一人でいるほうが好きだ」といった質問で外向性を測定している場合を考えます。明らかに、最後の質問に「6(とてもそう思う)」と回答した人は外向的とはみなされるべきではありません。したがって、6は1、5は2、1は6などとして逆転させる必要があります。これらの項目の得点を逆転させるには、次のようなシンプルな変換を使えばよいでしょう。
You can explore this transform by downloading and opening the data set
um_transform_ex1.omvin jamovi.例2:連続変数をカテゴリとして再コード化する
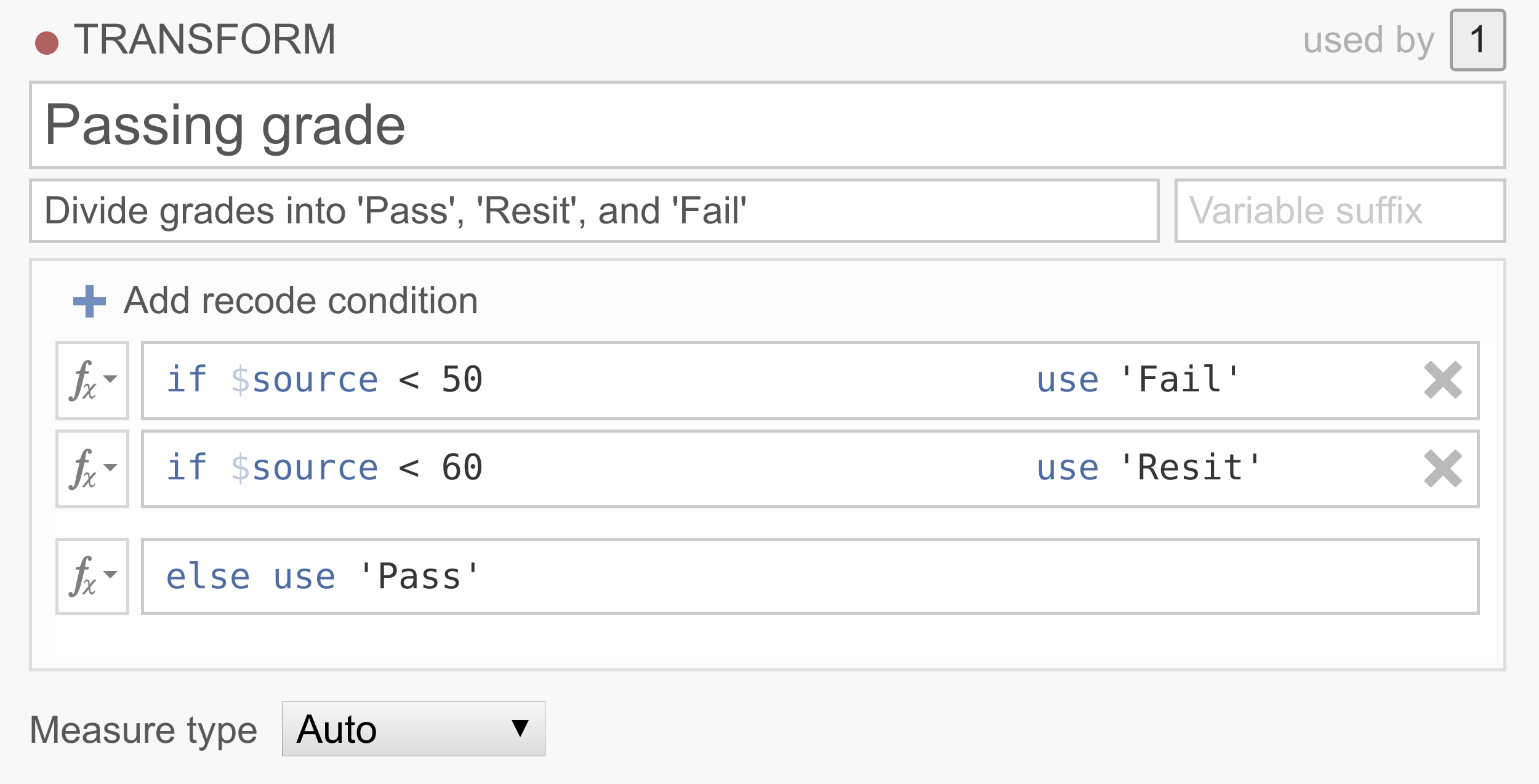
多くのデータセットでは、連続的な得点をカテゴリに再コード化したい場合があります。たとえば、0~100点の試験の点数に基づいて、人々を
合格、再試験、不合格の3つのグループのいずれかに分類したい場合などです。
Note that the conditions are executed in order, and that only the first rule that matches the case is applied to that case. So this transformation basically says that if the source variable has a value below 50, the value will be
Fail, if the source variable has a value between 50 and 60, the value will beResit, and if the source variable has a value above 60, the value will bePass. If you’d like an example data set to play around with, you can download and useum_transform_ex2.omv.例3:欠損値の置換
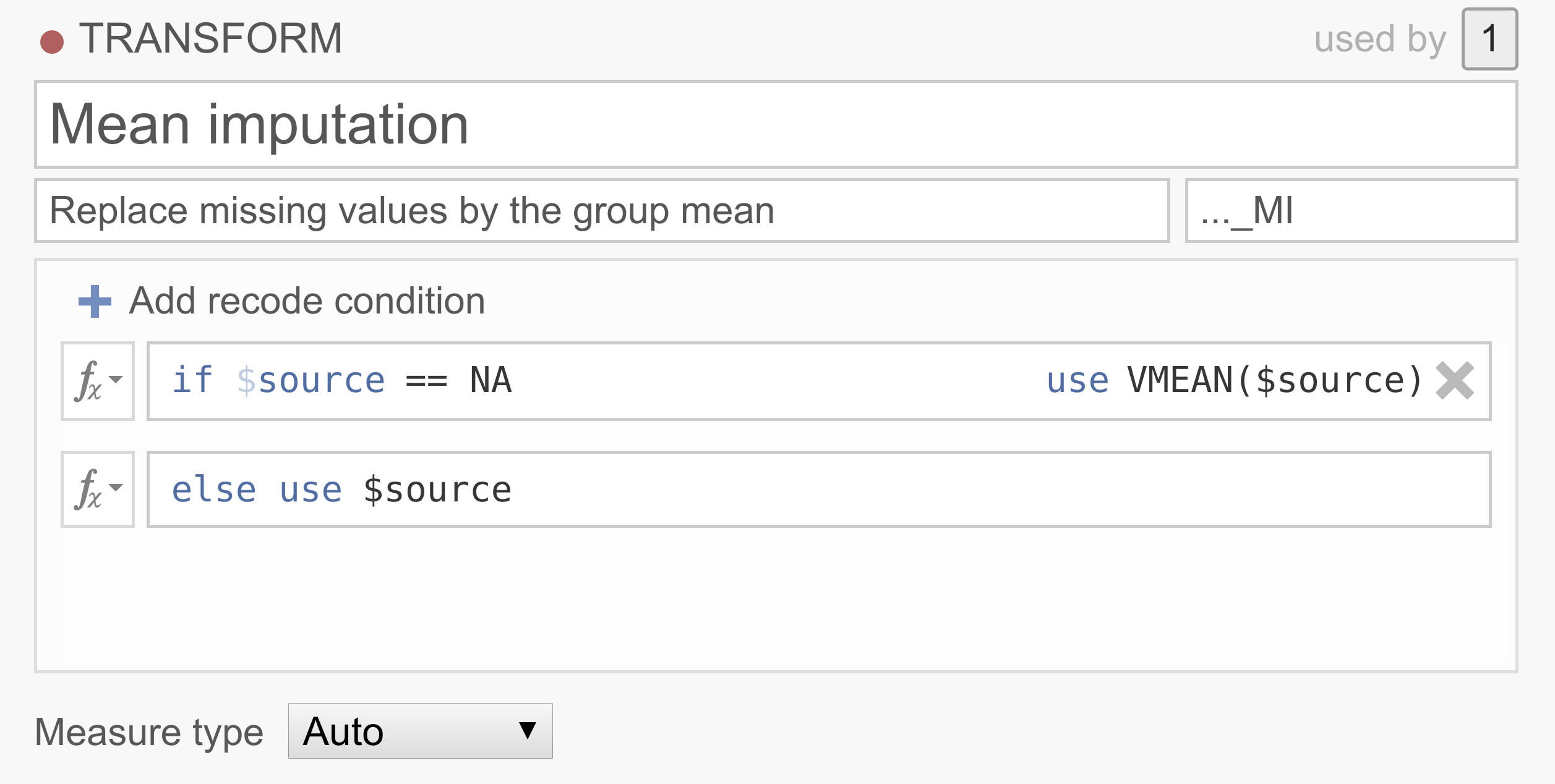
データセットに多くの欠損値があり、欠損値のある参加者を除外すると、多数の参加者が除外されることになるとします。欠損データに対処する方法はいくつかありますが、その中でも比較的一般的なのが代入法(imputation)です。非常にシンプルな代入法の1つに、欠損値を変数の平均値で置き換える「平均値代入法」があります。平均値代入法には多くの問題が伴うため、実際に使用すべきではありませんが、ここでは説明用のわかりやすい例として取り上げます...
Note that jamovi has borrowed NA from R to denote missing values. Don’t have a good data set handy? You can try it out yourself by downloading and opening the
um_transform_ex3.omvdata set.


フィルタ
jamoviのフィルタ機能を使うと、分析に含めたくない行を除外できます。たとえば、データの利用に明示的に同意した人の回答だけを含めたい場合や、左利きの人をすべて除外したい場合、あるいは実験課題で「チャンスレベル以下」の成績を取った人を除外したい場合などです。場合によっては、平均から3標準偏差以上離れた極端な得点を除外したいこともあるでしょう。
jamoviのフィルタは、jamoviの計算変数の数式システムを用いて構築されているため、任意の複雑な数式を作成できます。
行フィルタ
jamoviのフィルター機能を、jamovi付属の
Tooth Growthデータセット(☰→開く→データライブラリ)を使って説明します。データリボンのフィルタボタンを選択すると、フィルタ表示が開き、フィルタ1という新しいフィルタが作成されます。このショートビデオでは、9行目を除外するフィルタを指定しています。たとえば、9番目の参加者が単にアンケートシステムをテストしていただけで、本当の参加者ではなかったことが分かっている場合(
Tooth Growthは実際にはモルモットの歯の長さに関するデータですが、もしかすると9番目の参加者がウサギだったかもしれません)、次の数式を使って簡単にその行を除外できます。ROW() != 9この式における
!=は「等しくない」という意味です。Rのようなプログラミング言語を使ったことがあれば、とても馴染みがあるはずです。jamoviのフィルターは、数式が真でない行を除外します。今回の場合、ROW() != 9という式は9行目以外のすべての行で真となります。このフィルターを適用すると、「フィルタ1」列の9行目のチェックマークが×印に変わり、その行全体がグレー表示になります。今分析を実行すると、9行目が存在しないかのように処理されます。同様に、すでに何らかの分析を実行していた場合も、フィルター適用後は9行目を除いた値で再計算され、結果が更新されます。通常は、これよりも複雑なフィルタを使いたい場合が多いでしょう。
Tooth Growthの例には、モルモットにビタミンCまたはオレンジジュース(supp列でVCまたはOJとして記録)というサプリメントを、異なる用量(dose列)で与えたときの歯の長さ(len列)のデータが含まれています。ここで、用量が歯の長さに与える影響に興味があると仮定します。その場合、従属変数をlen、グループ変数をdoseとしてANOVAを行うことになるでしょう。しかし、ビタミンCの効果だけに関心があり、オレンジジュースの効果には関心がない場合、次の数式を使うことができます。supp == 'VC'必要であれば、この数式を
ROW() != 9の数式と一緒に指定することもできます。最初の数式の横にある小さな``+``をクリックしてフィルタ1に別の式として追加することもできますし、フィルタのダイアログボックスの左側にある大きな+を選択して追加のフィルタとして追加することもできます。後ほど説明しますが、既存のフィルターに式を追加する場合と、別のフィルターを作成する場合とでは、動作が異なる場合があります。しかし、この場合は違いがないので、既存のフィルターに追加します。この追加した式にも独自の列が表示され、チェックマークや×印を見ることで、どのフィルターや式が各行を除外しているのかを確認できます。今度は、平均から1.5標準偏差を超えるすべての歯の長さを分析から除外したいとしましょう。そのためには、zスコアを計算し、それが−1.5から1.5の間にあるかを確認します。次のいずれかの数式を使えばよいでしょう(2つ目の数式は、zスコアが何かを学生に説明するのにとてもよい方法です)。
-1.5 < Z(len) < 1.5 -1.5 < (len - VMEAN(len)) / VSTDEV(len) < 1.5jamovi には多くの関数が用意されており、数式ボックスの横にある小さな fx をクリックすると、それらを確認できます。
次に、フィルターの左側にある大きな
+をクリックして、このzスコアの数式を別のフィルターとして追加し、フィルタ2に追加しましょう。複数のフィルタがある場合、フィルタされた行は1つのフィルタから次のフィルタへと連鎖していきます。つまり、
フィルタ 1を通過した行だけがフィルタ2の計算に使用されます。この場合、zスコアの平均と標準偏差はビタミンCの行(および9行目を除く)だけに基づいて計算されます。対照的に、Z()フィルターをフィルタ1の追加の式として指定した場合、zスコアの平均と標準偏差はデータセット全体に基づいて計算されます。このようにして、どの行を分析に含めるかについて任意に複雑なルールを指定することができます(ただし、ルールは事前登録しておくべきです)。[1]列フィルタ
行フィルターがデータセット全体に適用されるのに対し、個々の列だけをフィルタリングしたい場合もあります。列フィルターは、一部の分析で特定の行をフィルタリングしたい場合に便利です。これは計算変数システムによって実現されます。計算変数を使うことで、不要な値が除外された、既存の列のコピーを作成できます。
Tooth Growthの例で、500と1000、または1000と2000の用量を別々に分析したいとします。そのためには、それぞれのサブセットごとに新しい列を作成します。例えば、jamoviのスプレッドシートでdose列を選択し、データタブから「計算」ボタンを選択します。これにより、右側にdose (2)という新しい列が作成され、フィルターと同様に数式を入力できます。今回は、以下のいずれかの数式を入力します(どちらも同じ処理ですが、2つ目の方が分かりやすいかもしれません)。
FILTER(dose, dose <= 1000) FILTER(dose, dose == 1000 or dose == 500)
FILTER()関数の最初の引数(この例ではdose)は、計算列で使用する値を指定します。2番目の引数は条件であり、この条件が満たされない場合、その値は空白(または「欠損値」)として扱われます。この数式を使うと、dose (2)列には500と1000の値だけが入り、2000の値は含まれません。列の名前は、より分かりやすいもの、たとえば
dose 5,10などに変更することもできます。同様に、FILTER(dose, dose != 500)という数式を使ってdose 10,20という列も作成できます。これで、lenを従属変数、dose 5,10をグループ変数として最初の分析を行い、もう一方ではdose 10,20をグループ変数として、2つの別々のANOVA(またはt検定)を実行できます。このようにして、異なる分析ごとに異なるフィルターを使うことができます。これに対して、行フィルタは すべて の分析に適用される点が異なります。
FILTER()を使えば、いわゆる「簡易的な分割変数」のようなこともできるのでは、と思った人もいるでしょう。 実際、FILTER()を使った変数分割は可能です。例えば、lenを2つの新しい列len_VCとlen_OJに分割するには、それぞれFILTER(len, supp == 'VC')とFILTER(len, supp == 'OJ')という関数を使います。こうすることで、2つの別々の列ができ、並べて分析できます。