Forfatter av avsnitt: Sebastian Jentschke
Hvordan identifiserer jeg ekstremverdier og filtrerer dem ut fra analysene?
- åpne
Data-fanen og velgFilter(enten ved å bruke symbolet i ikonlinjen eller symbolet i nederste venstre hjørne av jamovi-vinduet)for å få tilgang til funksjoner, trykk på ikonetfxi filterinnstillingenedet finnes også en bryter hvor du kan aktivere eller deaktivere filteret (se kommentaren i rødt nedenfor)du lukker filterinnstillingene ved å trykke på pilen i øverste høyre hjørne - det eksisterer tre store tilnærminger for å utelukke ekstremverdier:
basert på z-skårer (absoluttverdien bør være større enn 3,3; dette tilsvarer en sannsynlighet på 0,1 % = 1 / 1000; basert på en standard normalfordeling ~ parametrisk)
basert på IQR (som i et boksplott; basert på rangeringer og kvantiler ~ ikke-parametrisk)
basert på Mahalanobis-distansen (multivariate ekstremverdier)
for 1. og 2. finnes det funksjoner i jamovi (se neste kulepunkt), for 3. må du bruke R-kode (beskrevet to kulepunkt nedenfor); for 2. kan du også gjøre det visuelt (tre kulepunkt nedenfor) - du kan enten bruke et funksjonsbasert utvalg; funksjonene nedenfor filtrerer ut linjer basert på enten z-skårene (første linje), det interkvartilavstand (IQR, andre linje) eller ved å ekskludere visse rader / radtall (f.eks. basert på resultatet fra beregningen av Mahalanobis-distansen lenger nede; tredje linje):
MAXABSZ([VARIABLE1], [VARIABLE2], …)
MAXABSIQR([VARIABLE1], [VARIABLE2], …)
IFMISS(MATCH(ROW(), [ROWNUMBER 1], [ROWNUMBER 2], …), 1, 0)
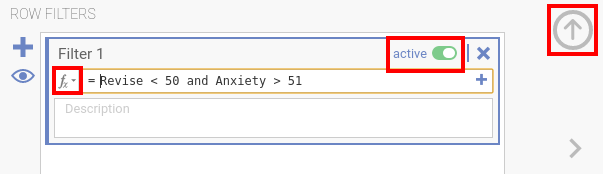 de følgende kodeeksemplene oppdager multivariate ekstremverdier basert på Mahalanobis-distansen (husk å tilpasse variabelnavnene i VL)
de følgende kodeeksemplene oppdager multivariate ekstremverdier basert på Mahalanobis-distansen (husk å tilpasse variabelnavnene i VL)# this list should contain the names of your INDEPENDENT VARIABLES # you should not include your dependent variables # if you already use a filter set it to inactive # hint: you can get the names of your variable with names(data) # the syntax is adjusted for jamovi (the data frame is called data, # but can easily be used within R by just changing data to the name of your data frame VL = c('dan.sleep', 'baby.sleep', 'day') # brief explanation: the code calculates the Mahalanobis distance for all variables in VL, # then calculates the p-value (pchisq) and show lines with variables that had a p-value < 0.001 row.names(data)[ pchisq(unname( mahalanobis(data[, VL], colMeans(data[, VL]), cov(data[, VL]))), df=length(VL), lower.tail=FALSE) < 0.001]
utgaven fraR-koden forteller deg hvilke linjer du bør velge bortdu bruker skriptene i Rj-editoren ved å bare kopiere dem og lim dem inn, kjør dem ved å trykke på ►-knappen (den lille grønne trekanten) - filterbetingelsene kan kombineres ved hjelp av de booleanske uttrykene
and/or:MAXABSZ([VARIABLE1], [VARIABLE2], …) < 3.3 and MAXABSIQR([VARIABLE1], [VARIABLE2], …) < 3 and IFMISS(MATCH(ROW(), [ROWNUMBER 1], [ROWNUMBER 2], …), 1, 0)
- i stedet for å bruke den andre linjen (
MAXABSIQR) kan du også velge bort tilfeller ved å ekskludere deres respektive radnumre i datasettet (som i den tredje linjen; du vil da visuelt sjekke ekstremverdiene i boksplottene underDescriptives, sørg for at avmerkingsboksenLabel outlierser satt og ekskludere radnumrene som er merket som ekstremverdier)