Forfatter av avsnitt: Jonathon Love
Regnearket
I jamovi representeres data i et regneark, der hver kolonne representerer en «variabel».
Datavariabler
De mest brukte variablene i jamovi er «Datavariabler». Disse variablene inneholder data som enten lastes inn fra en datafil, eller «skrevet inn» av brukeren. Datavariabler kan være én av tre datatyper:
Integer
Decimal
Textog en av fire målenivåer:

Nominal

Ordinal

Continuous

IDMålenivåne er angitt med symbolet i overskriften til variabelens kolonne. Merk at noen kombinasjoner av datatype og måletype ikke gir mening, og jamovi lar deg ikke velge disse.
NominalogOrdinaler for nominale og ordinale variabler.Continuouser for variabler med numeriske verdier som anses å være Intervall- eller forholdstall-skalaer (tilsvarerScalei SPSS). MåltypenIDer unik for jamovi. Den bør brukes for variabler som inneholder identifikatorer som du nesten aldri vil analysere (f.eks. et personnavn eller en deltaker-ID). Fordelen medIDer at jamovi ikke trenger å opprettholde en liste over nivåer internt. Det kan forbedre prosesseringshastighet når du bruker svært store datasett.Når du starter med et tomt regneark og skriver inn verdier, så endres dataene og målenivåene automatisk avhengig av dataene du skriver inn. Dette er en god måte å få en følelse av hvilke målenivåer brukes med hvilken slags data. På samme måte vil jamovi bestemme målenivået fra dataene i hver kolonne når du åpner en datafil. I begge tilfeller kan det hende at den automatiske tilnærmingen ikke er riktig, og det kan være nødvendig å manuelt angi data- og målenivå med å redigere variabelen.
Variabelredigering kan startes ved å velge
SetupfraData-fanen, dobbeltklikke på kolonneoverskriften eller ved å trykkeF3. Variabelredigering lar deg endre navnet på variabelen, og (for datavariabler) datatypen, målenivå, rekkefølgen på nivåene / trinnene og beskrivelse som vises for hvert nivå. Variabelredigering kan lukkes ved å klikke på lukkepilen eller ved å trykkeF3på nytt.Nye variabler kan settes inn eller legges til datasettet ved å bruke
Add-knappen fraData-fanen.Add-knappen lar også legge til Beregnede variabler.
Beregnede variabler
Beregnede variabler er variabler som tar verdien ved å utføre en beregning basert på andre variabler. Beregnede variabler kan brukes til en rekke formål, inkludert logaritmiske transformasjoner, z-transformasjoner, poengsummer, inversjon av skalaitems, gjennomsnitter, osv.
Beregnede variabler kan legges til datasettet, med
Legg til-knappen tilgjengelig påData-fanen. Dette vil produsere en inngavefelt hvor du kan spesifisere formelen. I tillegg er de vanlige aritmetiske operatorene tilgjengelige. Noen eksempler på formler er:A + B LOG10(len) MEAN(A, B) (dose - VMEAN(dose)) / VSTDEV(dose) Z(dose)I rekkefølge er disse summen av A og B, en logaritmisk transformasjon (med basis 10) av
len, gjennomsnittet avAogB, og z-transformasjon fordose(med to forskjellige beregningsmåter).Det er mange flere funksjoner tilgjengelig.
V-funksjoner
En rekke funksjoner kommer i par, den ene prefikset med en
Vog den andre ikke.V-funksjoner utfører sin beregning på en variabel som en helhet, mens ikke-V-funksjoner utfører sin beregning rad for rad. For eksempel vilMEAN(A, B)produsere gjennomsnittet avAogBfor hver rad mensVMEAN(A)gir gjennomsnittet av alle verdiene iA.I tillegg støtter
V-funksjoner etgroup_by-argument. Når engroup_by-variabel er spesifisert, beregnes det en separat verdi for hvert nivå avgroup_by-variabelen. I følgende eksempel:VMEAN(len, group_by=dose)Et separat gjennomsnitt beregnes for hvert nivå av
dose, og hver verdi i den beregnede variabelen vil være gjennomsnittet som tilsvarer radens verdi avdose.
Transformerte (omkoderte) variabler
Selv om beregnede variabler er gode for mange operasjoner (f.eks. beregning av sumskårer, generering av data osv.), kan de være litt tungvinte å bruke når du vil omkode eller transformere flere variabler (f.eks. ved omvendt skåring av flere svar i et undersøkelsesdatasett). Med «transformerte variabler» kan du enkelt omkode eksisterende variabler og bruke den samme transformasjonen på mange variabler samtidig.
Lage transformerte variabler
Når du transformerer eller omkoder variabler i jamovi, opprettes det en ny «transformert variabel» for den opprinnelige «kildevariabelen». På denne måten vil du alltid ha tilgang til de opprinnelige, ikke-transformerte dataene ved behov. For å transformere en variabel velger du først kolonnen(e) du ønsker å transformere. Du kan velge en blokk med kolonner ved å klikke på den første kolonneoverskriften i blokken og deretter klikke på den siste kolonneoverskriften i blokken mens du holder ⇧-tasten nede. Alternativt kan du velge/oppheve valget av enkeltkolonner ved å klikke på kolonneoverskriftene mens du holder Ctrl-/Cmd-tasten nede. Når du har valgt, kan du enten velge
Transformfra datafanen, eller høyreklikke og velgeTransformfra menyen.Høyreklikk enten på en av de valgte variablene, og klikk på
Transform...:
eller gå til
Data-båndet, og klikk påTransformer
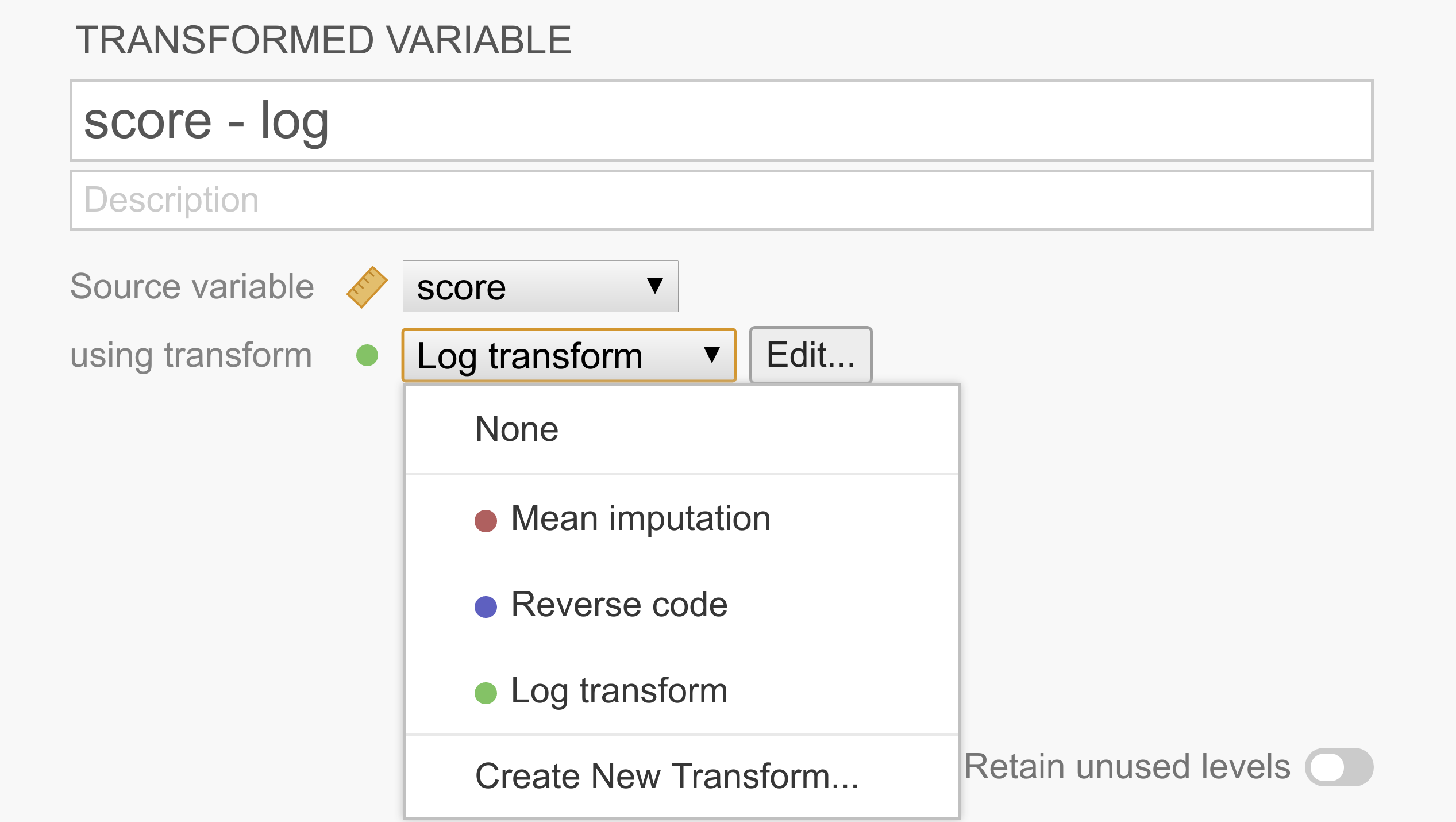
Dette konstruerer en ny «transformert variabel» for hver kolonne som ble valgt. I det følgende eksempelet hadde vi bare valgt én variabel, så vi setter bare opp transformasjonen for én variabel (kalt score - log), men det er ingen grunn til at vi ikke kan gjøre mer på én gang.
Som det fremgår av figuren ovenfor, har hver transformerte variabel en «kildevariabel», som representerer den opprinnelige, ikke-transformerte variabelen, og en transformasjon, som representerer regler for å transformere kildevariabelen til den transformerte variabelen. Etter at en transformasjon er opprettet, er den tilgjengelig fra listen og kan enkelt gjenbrukes for andre transformerte variabler.
Hvis du ikke ennå har definert den aktuelle transformasjonen, kan du velge
Lag en ny transformasjon...fra listen.Lag en ny transformasjon
Etter å ha klikket på
Lag en ny transformasjon...åpner seg transformasjonseditoren i visningen:
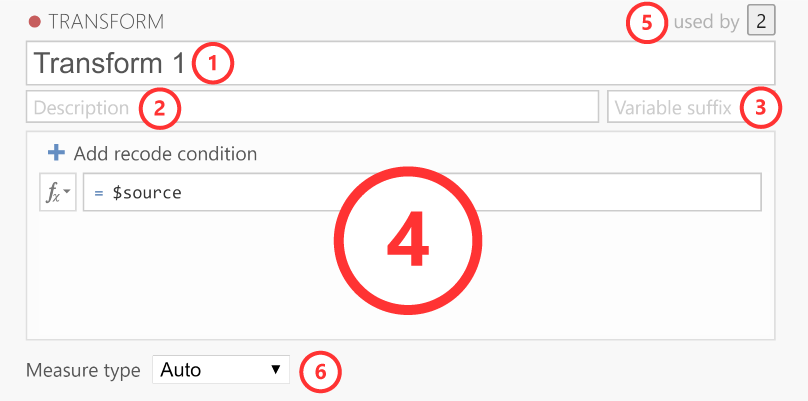
Transformasjonseditoren inneholder disse elementene.
Navn: Navnet på transformasjonen.
Beskrivelse: Her kan du gi en beskrivelse av transformasjonen, slik at du (og andre) vet hva den gjør.
Variabelsuffiks (valgfritt): Her kan du definere standard navneformatering for den transformerte variabelen. Som standard blir variabelsuffikset lagt til kildevariabelnavnet med en bindestrek (-) mellom. Du kan imidlertid overstyre dette ved å bruke tre prikker (…), som da erstattes av variabelnavnet. Hvis du for eksempel transformerer en variabel som heter Q1, kan du bruke variabelsuffikser til å bruke følgende navngivningsskjemaer (hvis du lar det stå tomt, brukes transformasjonsnavnet som variabelsuffiks):
log→Q1 - log..._log→Q1_loglog(...)→log(Q1)Transformasjon: Denne delen inneholder regler og formler for transformasjonen. Du kan bruke alle de samme funksjonene som er tilgjengelige i beregnede variabler, og for å referere til verdiene i kildekolonnen (slik at du kan transformere dem), kan du bruke det spesielle nøkkelordet
$source. Hvis du vil omkode en variabel til flere grupper, er det enklest å bruke flere betingelser. For å legge til flere betingelser (dvs. if-betingelser) klikker du på knappenLegg til omkodingsbetingelse:Brukes av: Angir hvor mange variabler som bruker denne transformasjonen. Hvis du klikker på tallet, får du en liste over disse variablene.
Måltype: Som standard er måltypen satt til Auto, som automatisk bestemmer måltypen fra transformasjonen. Hvis Auto ikke bestemmer måltypen riktig, kan du imidlertid overstyre den her.
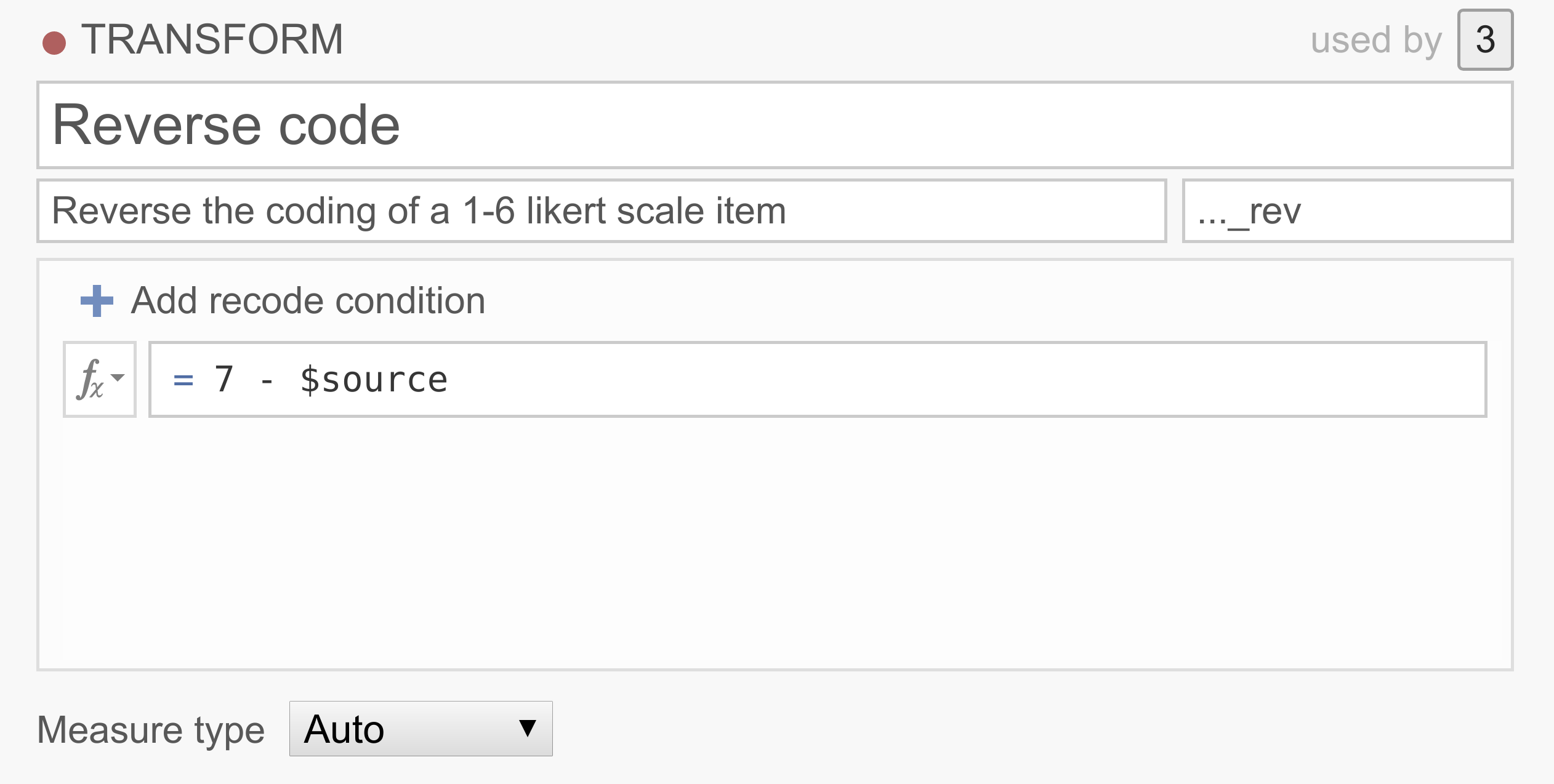
Eksempel 1: Inversjon av spørsmål / items
Data fra spørreundersøkelser inneholder ofte ett eller flere spørsmål der verdiene må inverteres før de kan analyseres. Vi kan for eksempel måle ekstraversjon med spørsmålene «Jeg liker å gå på fest», «Jeg liker å være sammen med folk» og «Jeg foretrekker å holde meg for meg selv». En person som svarer 6 (helt enig) på det siste spørsmålet, bør åpenbart ikke regnes som ekstravertert, og 6 bør derfor behandles som 1, 5 som 2, 1 som 6 osv. For å invertere skåringen av disse spørsmålene kan vi bruke den følgende enkle transformasjonen:
You can explore this transform by downloading and opening the data set
um_transform_ex1.omvin jamovi.Eksempel 2: Omkoding av kontinuerlige variabler til kategorier
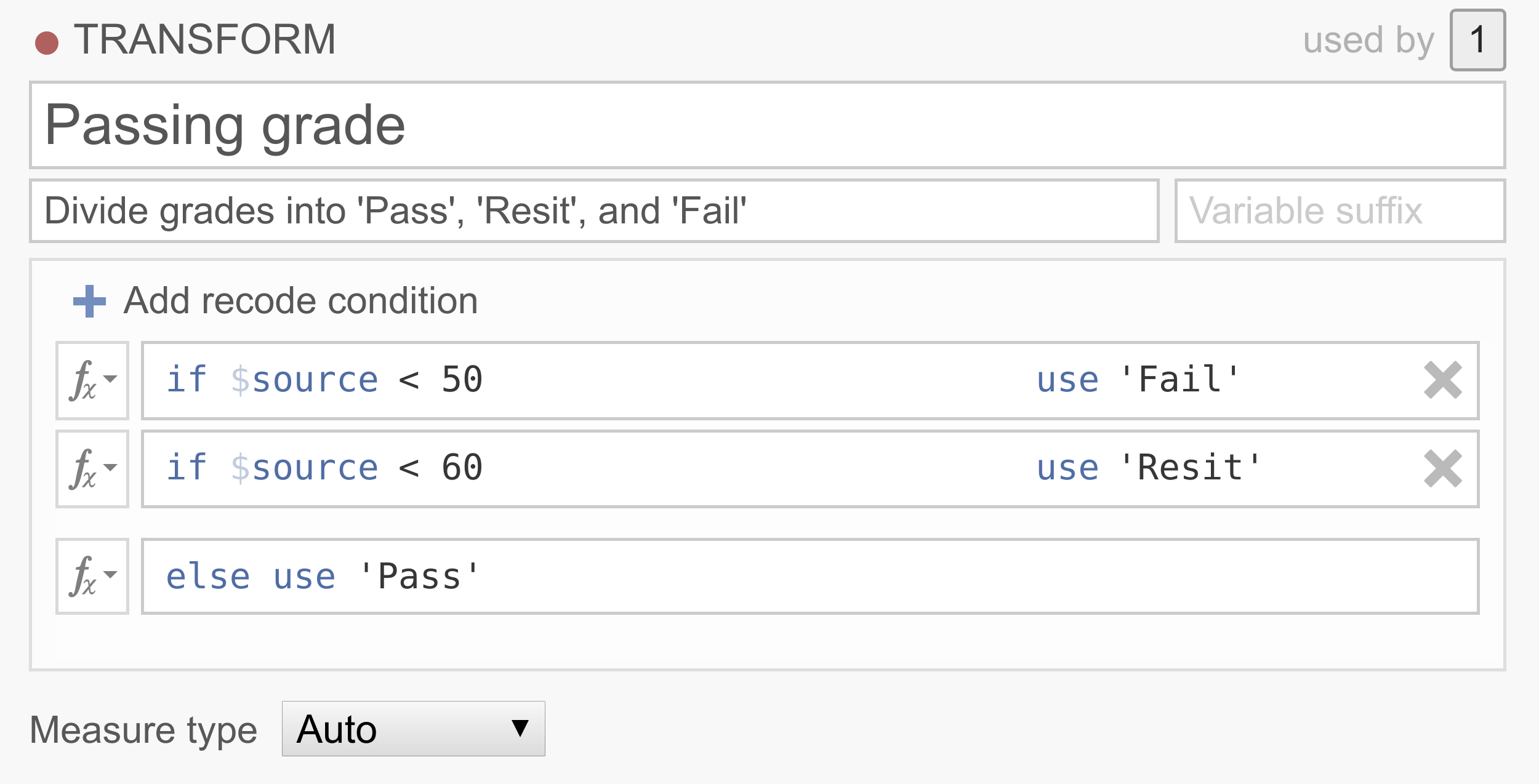
I mange datasett ønsker folk å omkode de kontinuerlige resultatene sine til kategorier. For eksempel kan det være lurt å klassifisere personer, basert på testresultatene deres fra 0-100 %, i én av tre grupper:
Pass,ResitogFail.
Note that the conditions are executed in order, and that only the first rule that matches the case is applied to that case. So this transformation basically says that if the source variable has a value below 50, the value will be
Fail, if the source variable has a value between 50 and 60, the value will beResit, and if the source variable has a value above 60, the value will bePass. If you’d like an example data set to play around with, you can download and useum_transform_ex2.omv.Eksempel 3: Erstatning av manglende verdier
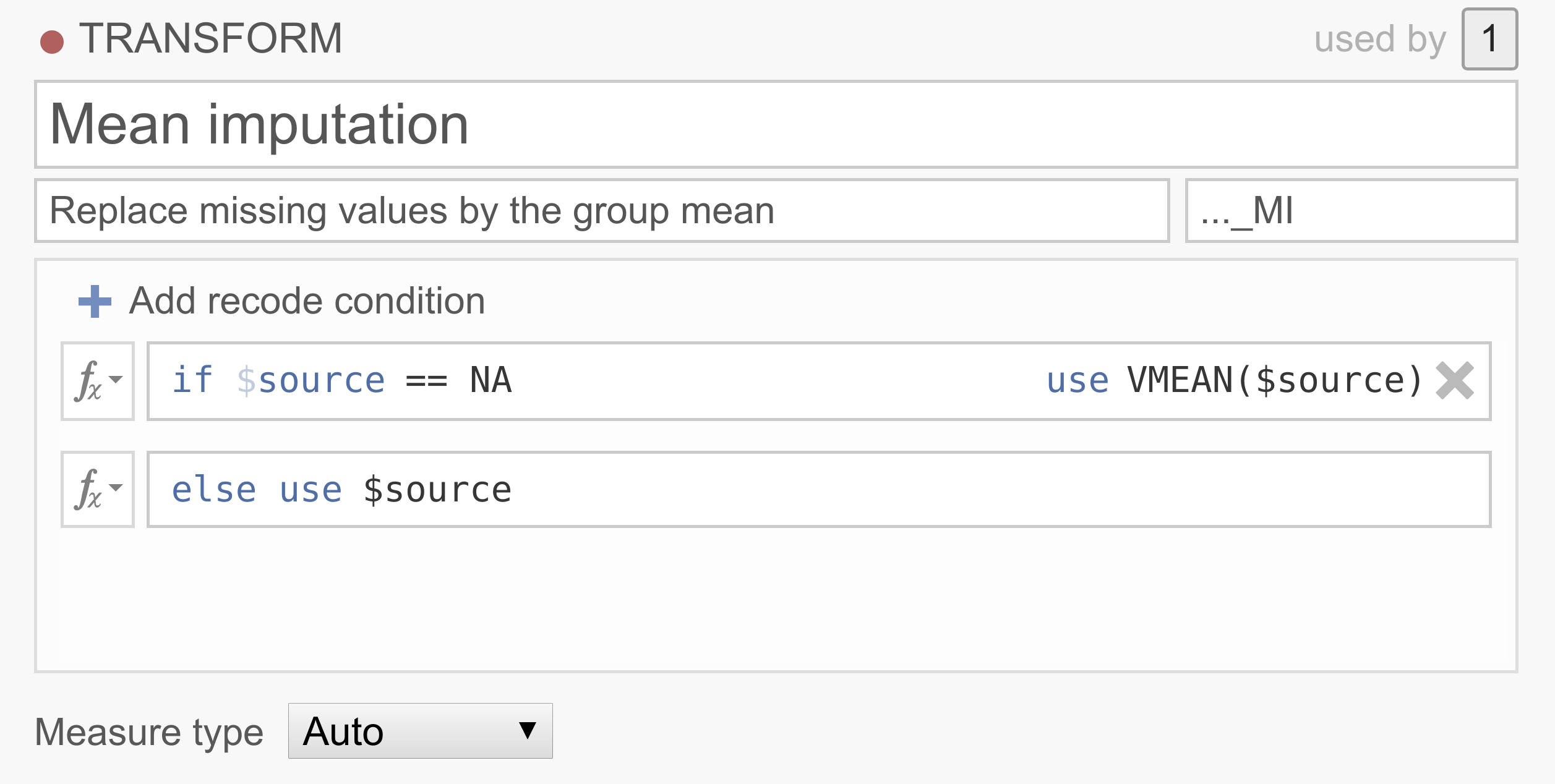
La oss antar at datasettet ditt har mange manglende verdier, og at det å fjerne deltakere med manglende verdier vil føre til et stort tap av deltakere. Det finnes en rekke måter å håndtere manglende data på, og imputering er en ganske vanlig metode. En ganske enkel imputeringsmetode erstatter de manglende verdiene med variabelens gjennomsnitt (dvs. gjennomsnittssubstitusjon). Selv om det er en rekke problemer forbundet med gjennomsnittssubstitusjon, og du sannsynligvis aldri bør gjøre det, er det en fin demonstrasjon…
Note that jamovi has borrowed NA from R to denote missing values. Don’t have a good data set handy? You can try it out yourself by downloading and opening the
um_transform_ex3.omvdata set.
Filtre
Med filtre i jamovi kan du filtrere bort rader som du ikke ønsker å inkludere i analysen. Det kan for eksempel være at du bare vil ta med svarene til personer som har gitt sitt eksplisitte samtykke til at dataene deres kan brukes, eller at du vil ekskludere alle venstrehendte personer, eller kanskje personer som skårer «under sjansenivå» i en eksperimentell oppgave. I noen tilfeller ønsker du bare å ekskludere ekstreme skårer, for eksempel de som skårer mer enn tre standardavvik fra gjennomsnittet.
Filtrene i jamovi er bygget på jamovis beregnede variabel-formelsystem. Det gjør det mulig å bygge svært komplekse formler.
Radfiltre
jamovi-filtrene demonstreres ved hjelp av datasettet
Tooth Growthsom følger med jamovi (☰→Open→Data Library). VelgFilters buttonfra båndetData. Dette åpner filtervisningen og oppretter et nytt filter som heterFilter 1.I den korte videoen spesifiserer vi et filter for å ekskludere den niende raden. Kanskje vi vet at den niende deltakeren var en som bare testet undersøkelsessystemet, og ikke en ekte deltaker (
Tooth Growthhandler faktisk om lengden på marsvintenner, så kanskje vi vet at den niende deltakeren var en kanin). Vi kan ganske enkelt ekskludere dem med formelen:ROW() != 9I dette uttrykket betyr
!=«does not equal». Hvis du noen gang har brukt et programmeringsspråk som R, bør dette være kjent. Filtre i jamovi ekskluderer radene som formelen ikke er sann for. I dette tilfellet er uttrykketROW() != 9sant for alle rader unntatt den niende raden. Når vi bruker dette filteret, endres krysset i kolonnenFilter 1i den niende raden til et kryss, og hele raden blir grå. Hvis vi skulle kjøre en analyse nå, ville den kjøres som om den niende raden ikke var der. På samme måte, hvis vi allerede hadde kjørt noen analyser, ville de kjøres på nytt, og resultatene ville oppdateres til verdier som ikke bruker den niende raden.Vanligvis vil vi gjerne ha mer komplekse filtre enn dette! Eksempelet
Tooth Growthinneholder lengden på tenner fra marsvin (kolonnenlen) som har fått ulike doser (kolonnendose) av kosttilskudd (registrert i kolonnensuppsom C-vitamin:VCeller appelsinjuice:OJ). La oss anta at vi er interessert i effekten av dosering på tannlengden. Vi kan kjøre en ANOVA medlensom avhengig variabel, ogdosesom grupperingsvariabel. Men la oss si at vi bare er interessert i effekten av vitamin C, og ikke av appelsinjuice. Da kan vi bruke formelen:supp == 'VC'Vi kan faktisk spesifisere denne formelen i tillegg til
ROW() != 9-formelen hvis vi ønsker det. Vi kan legge den til som et nytt uttrykk tilFilter 1(ved å klikke på det lille+ved siden av den første formelen), eller vi kan legge den til som et ekstra filter (ved å velge det store+til venstre i filterdialogboksen). Som vi skal se, fungerer det å legge til et uttrykk i et eksisterende filter ikke på nøyaktig samme måte som å opprette et eget filter. I dette tilfellet spiller det imidlertid ingen rolle, så vi legger det bare til i det eksisterende filteret. Dette ekstra uttrykket blir også representert med sin egen kolonne, og ved å se på flått og kryss kan vi se hvilket filter eller uttrykk som er ansvarlig for å ekskludere hver rad.Men la oss si at vi ønsker å ekskludere alle tannlengder som var mer enn 1,5 standardavvik fra gjennomsnittet, fra analysen. For å gjøre dette tar vi en z-score og sjekker at den ligger mellom -1,5 og 1,5. Vi kan bruke en av følgende formler (den andre formelen er en fin måte å demonstrere for elevene hva en z-score er):
-1.5 < Z(len) < 1.5 -1.5 < (len - VMEAN(len)) / VSTDEV(len) < 1.5Det finnes mange funksjoner i jamovi, og du kan se dem ved å klikke på den lille fx ved siden av formelboksen.
La oss nå legge til denne formelen for z-transformering i et eget filter ved å klikke på det store
+til venstre for filtrene, og legge den tilFilter 2.Med flere filtre behandles de filtrerte radene i kaskader fra det første filteret til de neste. Det er altså bare de radene som slippes gjennom av
Filter 1som brukes i beregningene forFilter 2. I dette tilfellet vil gjennomsnittet og standardavviket for de z-transformerte verdiene kun være basert på radene med vitamin C (og heller ikke på rad 9). Hvis vi derimot hadde spesifisertZ()-filteret vårt som et ekstra uttrykk iFilter 1, ville gjennomsnittet og standardavviket for de z-transformerte verdiene være basert på hele datasettet. På denne måten kan du spesifisere vilkårlig komplekse regler for når en rad skal inkluderes i analyser eller ikke (men du bør forhåndsregistrere reglene dine).[1]Kolonnefiltre
Mens radfiltre brukes på datasettet som helhet, vil du noen ganger bare filtrere enkelte kolonner. Kolonnefiltre er nyttige når du ønsker å filtrere noen rader for noen analyser, men ikke for alle. Dette gjøres ved hjelp av systemet med beregnede variabler. Med de beregnede variablene lager vi en kopi av en eksisterende kolonne, hvor de uønskede verdiene blir ekskludert.
I eksemplet med tannvekst ønsker vi kanskje å analysere dosene 500 og 1000, og 1000 og 2000 hver for seg. For å gjøre dette oppretter vi en ny kolonne for hvert delsett. I vårt eksempel kan vi velge kolonnen
dosei jamovi-regnearket, og deretter velge knappenBeregniData-båndet. Dette oppretter en ny kolonne til høyre som heterdose (2), og på samme måte som for filtrene kan vi legge inn en formel. i dette tilfellet legger vi inn en av formlene nedenfor (de gjør det samme, den andre er kanskje lettere å forstå):FILTER(dose, dose <= 1000) FILTER(dose, dose == 1000 or dose == 500)Det første argumentet til funksjonen
FILTER()(i dette eksempelet dose) er hvilke verdier som skal brukes i den beregnede kolonnen. Det andre argumentet er betingelsen; når denne betingelsen ikke er oppfylt, blir verdien blank (eller som en «manglende verdi», hvis du foretrekker det). Med denne formelen inneholder kolonnendose (2)alle verdiene i500og1000, mens verdiene i2000ikke er der.Vi kan også endre navnet på kolonnen til noe mer beskrivende, for eksempel
dose 5,10. På samme måte kan vi opprette en kolonnedose 10,20med formelenFILTER(dose, dose != 500). Nå kan vi kjøre to separate ANOVAer (eller t-tester) medlensom avhengig variabel, ogdose 5,10som den ene grupperingsvariabelen i den første analysen, ogdose 10,20i den andre. På denne måten kan vi bruke forskjellige filtre til forskjellige analyser. I motsetning til radfiltre som brukes på alle analysene.Du har kanskje også tenkt på at vi med
FILTER()kan dele opp analysene: Du kan lage for eksempel to grupper ved å brukeFILTER(), og vi kan splitteleni to nye kolonnerlen_VCoglen_OJmed henholdsvis funksjoneneFILTER(len, supp == 'VC')ogFILTER(len, supp == 'OJ'). Dette resulterer i to separate kolonner som kan analyseres side om side.