Forfatter av avsnitt: Jonathon Love
Kombinere jamovi og R
En stor fordel med jamovi er at det er bygget på toppen av det statistiske språket R. Det gjør det veldig enkelt å få tilgang til R fra jamovi, og til jamovi fra R. Syntaksmodusen, Rj, jmvconnect og jmvReadWrite hjelper deg med å oppnå det.
Syntaksmodus
jamovi tilbyr en «R Syntax Mode». I denne modusen produserer jamovi R-kode for hver analyse. For å bytte til syntaksmodus, velg programmenyen (⋮) øverst til høyre i jamovi, og merk av for
Syntax modeder. Det er mulig å gå ut av syntaksmodus ved å klikke av markeringen.I syntaksmodus fortsetter analyser å fungere som før, men nå produserer de R-syntaks. Som alle resultatobjekter i jamovi, kan du høyreklikke på disse elementene (inkludert R-syntaksen) og kopiere og lime dem inn, for eksempel i en R-sesjon. Alle analysene som er inkludert i jamovi er tilgjengelige i en R-sesjon gjennom R-pakken jmv.
Den medfølgende R-syntaksen inkluderer ikke dataimport-trinnet, men dette kan enkelt gjøres ved å bruke R-pakkene
jmvconnectogjmvReadWrite(forklart mer detaljert nedenfor). MedjmvReadWritekan du lese og skrive jamovi-datafiler (.omv) i R, og medjmvconnectkan du få tilgang til datasett som du har åpnet i jamovi-økten din, fra R.
Rj-editor
Rj Editorkan brukes til å analysere data ved bruk avRdirekte i jamovi. På denne måten kan du også bruke de R-pakkene du liker best fra jamovi. Rj ` er en av de mange tillegsmodulene for jamovi (se Installer moduler i jamovi).
Det er mange grunner for å bruke
R-kode: Det finnes mange analyser tilgjengelig i R-pakker som (ennå) ikke er gjort tilgjengelige som jamovi-moduler, ogRjlar deg bruke disse analysene fra jamovi. I tillegg kan du bruke sløyfer og if-setninger, noe som blant annet muliggjør gjentatte analyser, betingede analyser og simuleringsstudier.For noen vil bruk av
Ri et regneark være et ideelt sted å begynne å læreR. For andre kan det være en enkel måte å deleR-analyser med kolleger som ikke har avansert teknisk kunnskap (og noen foretrekker rett og slett å bruke kode).For å kjøre en R-analyse velger du
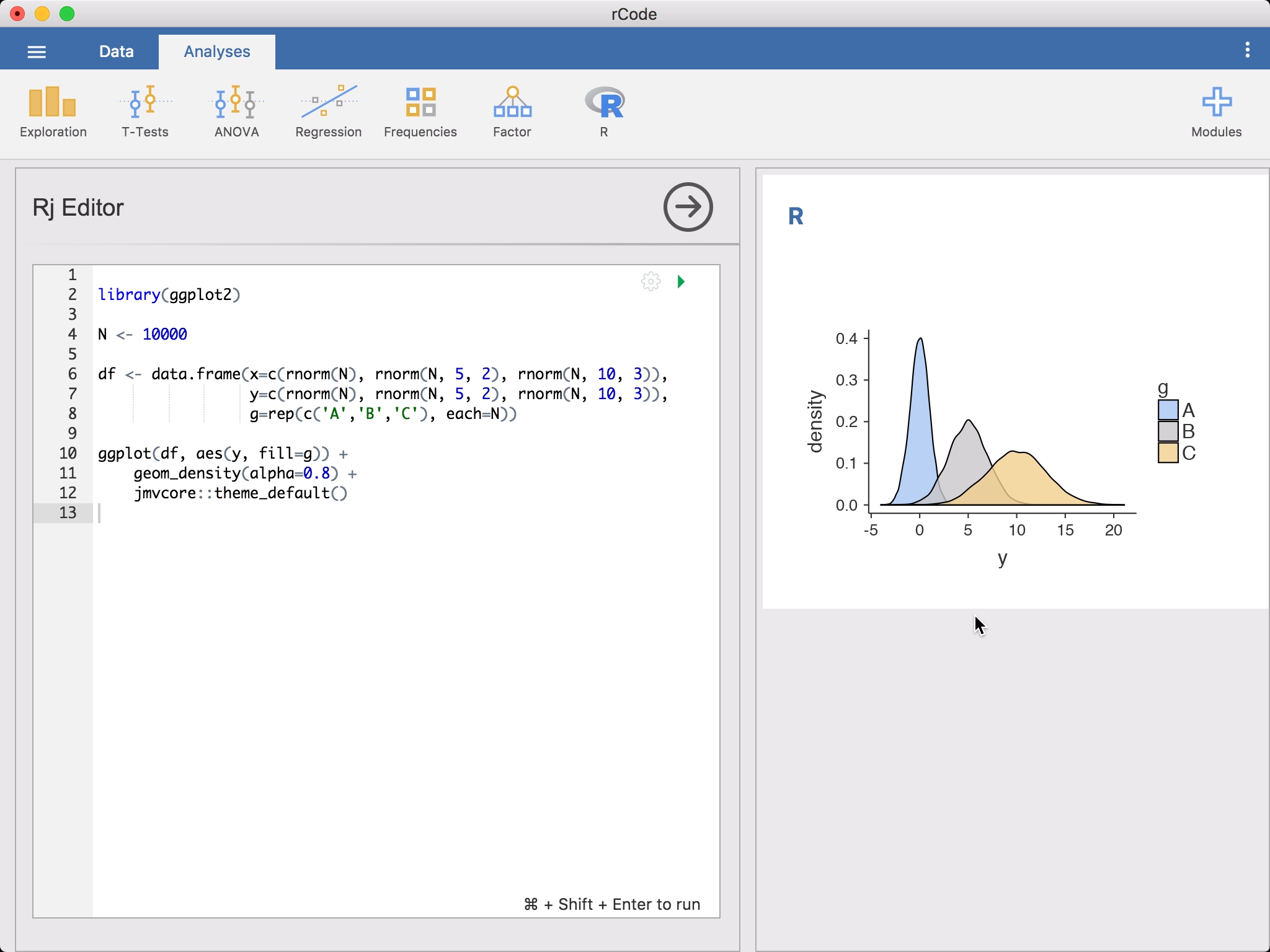
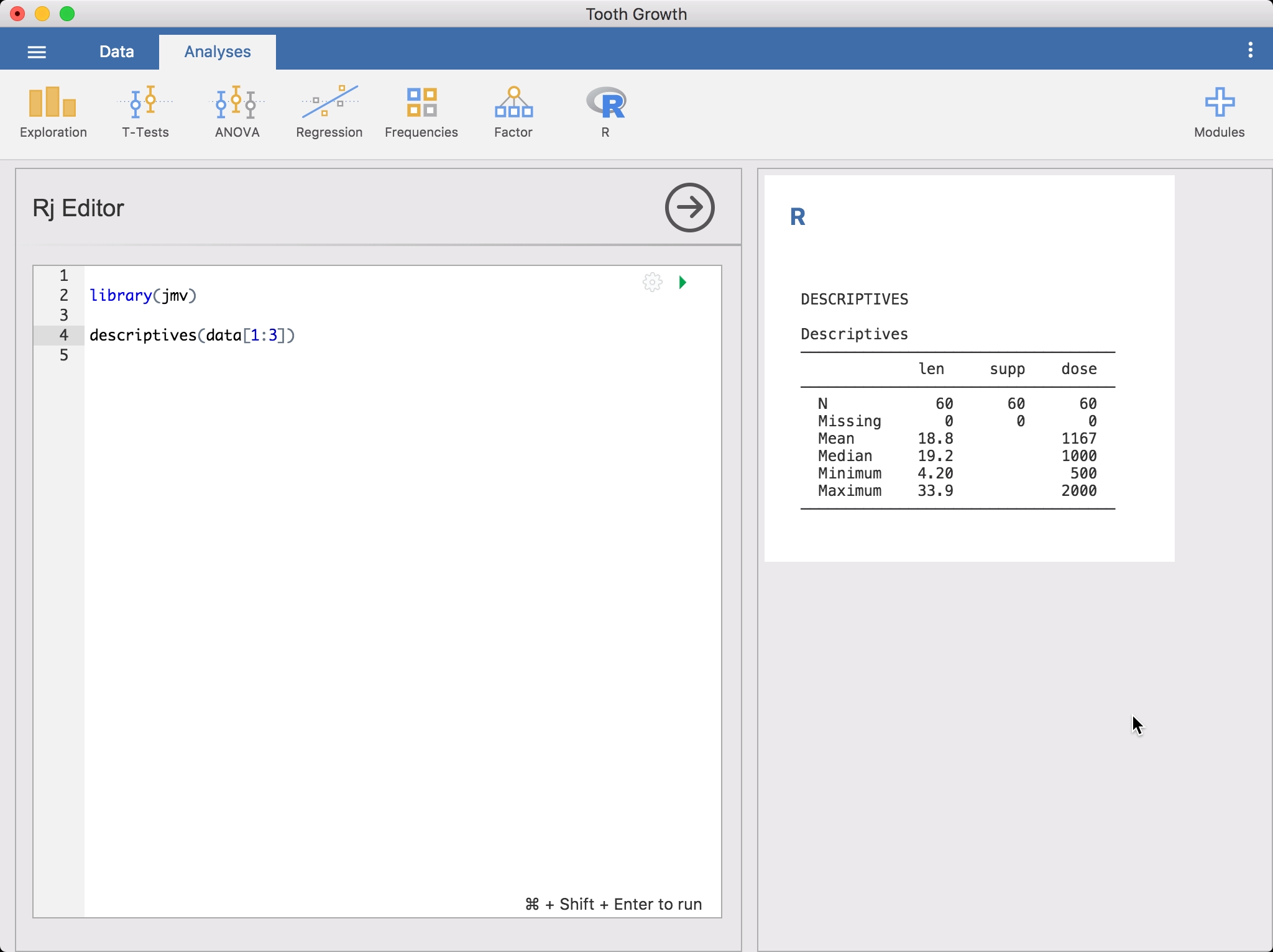
Rj EditorfraR-ikonet i båndetAnalyser. Da får du opp redigeringsprogrammet der du kan skrive innR-koden. Datasettet du har åpnet i jamovi, er tilgjengelig for deg som endata.framesomdata. For å komme i gang kan du kjøredescriptivespå det.
Eller hvis du foretrekker
dplyr-tilnærming, kan du skrive:library(jmv) library(dplyr) library(magrittr) select(data, 1:3) %>% descriptives()Du vil legge merke til at
Rjautomatisk foreslår funksjonsnavn når du skriver inn denne koden. For å kjøre koden klikker du på den grønne trekanten eller trykker Control + Shift + Enter (eller ⌘ + Shift + Enter hvis du bruker Mac). jamovi kjører daR-koden, og resultatene vises i resultatpanelet på samme måte som andre analyser. Du kan fortsette å gjøre endringer i koden, og deretter kjøre den på nytt.Som standard bruker
Rjversjonen avRsom følger med jamovi. Denne inneholder mange pakker (jmvog alle dens avhengigheter), og vil være tilstrekkelig for de fleste. Hvis du trenger å gjøre bruk av ytterligereR-pakker, må du brukeSystem Rversjonen. Hvis du velger ⚙ (øverst til høyre i kodeboksen), vil du se et alternativ for å endreR versionsom brukes. VersjonenSystem Rbruker den versjonen avRsom du har installert på systemet ditt. Dette har den fordelen atR-koden din nå har tilgang til alle pakkene du har installert for den versjonen avR. Det siste du trenger er å ha R-pakkenjmvconnectinstallert i R-biblioteket på systemet ditt.
R-pakken jmvconnect
R-pakken
jmvconnectgirR-versjonen på systemet ditt tilgang til jamovi-datasettene. Du kan installere den iRmed:install.packages('jmvconnect')Når dette er gjort, skal det være problemfritt å gå fra
jamovi RtilSystem R.Det er verdt å huske at det blir litt mer komplisert å dele jamovi-filer med kolleger når du bruker
System R-versjonen. Hvis de ønsker å gjøre endringer og kjøre analysene dine på nytt, må de ha de sammeR-pakkene installert som ble brukt i disse analysene - det er prisen for fleksibilitet!Når
RjkjørerRkode, gjør den som standard hele datasettet tilgjengelig som en dataramme kaltdata. Det er imidlertid sannsynlig at analysen din bare bruker noen få kolonner, og ikke trenger hele datasettet. Du kan begrense kolonnene som gjøres tilgjengelige for analysen, ved å inkludere en spesiell kommentar øverst i skriptet på følgende måte:# (column1, column2, column3) library(jmv) ...I dette tilfellet vil bare de navngitte kolonnene vises i datarammen. Dette kan gjøre analysen raskere, særlig hvis du jobber med store datasett. I tillegg får jamovi beskjed om at analysen bare bruker disse kolonnene, og analysen trenger ikke å kjøres på nytt hvis det gjøres endringer i andre kolonner.
Det kan hende at du ønsker å gå over til en
R-sesjon for å analysere et datasett. Det er her R-pakkenjmvconnectkommer til nytte. Medjmvconnectkan du lese datasettene fra en jamovi-instans som kjører, til en R-sesjon. Den har to funksjoner: what() viser de tilgjengelige datasettene, ogread()leser dem. Du kan for eksempel bruke:> library(jmvconnect) > what() Available Data Sets ───────────────────────────────────── Title Rows Cols ───────────────────────────────────── 1 iris 150 5 2 Tooth Growth 60 3 ─────────────────────────────────────og deretter lese datasettet med en av disse to kommandoene:
data <- read('Tooth Growth') data <- read(2)
R-pakken jmvReadWrite
R-pakken
jmvReadWriteleser og skriver jamovi-datafiler (.omv) iR. Den kan installeres med:install.packages('jmvReadWrite')Et typisk bruksområde er hvis du ønsker å behandle et stort antall resultatfiler (f.eks. CSV-filer fra flere deltakere i et eksperiment eller med svar fra ulike spørreskjemaer). Det er ofte enklest å behandle slike store datamengder i
R. Når du har satt sammen datasettet ditt fra disse filene, kan du skrive det ved hjelp avwrite_omv()-funksjonen.library(jmvReadWrite) # assemble your data set (named dtaSet)... write_omv(dtaSet, "FILENAME.omv")På samme måte tillater
read_omv-funksjonen å lese jamovi-datafiler inn iR. Et annet typisk bruksområde er å lese en datafil, gjøre manipulasjoner ved dataene som for tiden ikke er implementert i jamovi, og deretter skrive tilbake den modifiserte filen (i jamovi-filformatet).library(jmvReadWrite) dtaSet <- read_omv("FILENAME.omv") # do some modifications to your data set write_omv(dtaSet, "FILENAME.omv")I tillegg finnes det en del hjelpefunksjoner i
jmvReadWrite. Disse muliggjør operasjoner som omorganisering av kolonnene / variablene i et datasett (arrange_cols_omv), konvertering av en større mengde datafiler til jamovi-filformatet (convert_to_omv; f.eks. fra et statistikkprogramvare du tidligere har brukt), konvertere datafiler fra long- til wide-format (long2wide_omv) og fra wide- til long-format (wide2long_omv), legge til kolloner fra andre datasett (merge_cols_omv), legge til deltakere fra et annet datasett (merge_rows_omv), eller sortere et datasett etter en eller flere variabler (sort_omv).Et annet mulig bruksområde for
read_omver oppretting av R markdown-filer med resultatene av jamovi-analysene dine. ParameterengetSynavgjør om syntaksen til analysene i filen skal hentes ut. For å kjøre syntaksen må R-pakkenjmvvære installert. Hvis du ønsker å arbeide med resultatene i etterkant, anbefales det at du tilordner dem til en variabel (se den andreevalnedenfor). Tabeller fra resultatene kan konverteres til en data frame med funksjonenasDF(f.eks.result$main$asDF).library(jmvReadWrite) library(jmv) data <- read_omv("FILENAME.omv", getSyn = TRUE) # the analyses are stored in the attribute syntax attr(data, "syntax") # with using an index, the n-th analysis can be accessed (first line) # and run / evaluated (second line) attr(data, "syntax")[[1]] eval(parse(text = attr(data, "syntax")[[1]])) # often it is more useful to assign the results to a variable when # running analyses and later on use the contents of that variable eval(parse(text = paste0("result = ", attr(data, "syntax")[[2]]))) names(result) # (returns the names of the output elements - tables, figures, and # groups: sub-headings, e.g., Estimated Marginal Means in an ANOVA, # that contain further tables and figures)