Autor des Abschnitts: Sebastian Jentschke
Wie erkenne ich Ausreißer und filtere sie aus den Analysen heraus?
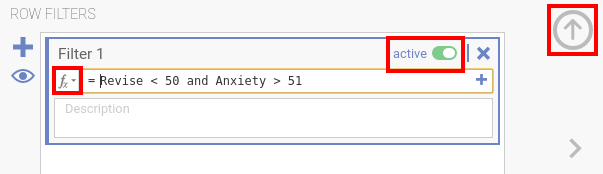
- Öffnen Sie die Registerkarte
Dataund wählen SieFilter(entweder über das Symbol in der Symbolleiste oder über das Symbol in der unteren linken Ecke des jamovi-Fensters)um auf die Funktionen zuzugreifen, drücken Sie das Symbolfxin den Filtereinstellungenes gibt auch einen Schalter, mit dem Sie den Filter aktivieren oder deaktivieren können (siehe den roten Kommentar weiter unten)Sie schließen die Filtereinstellungen, indem Sie auf den Pfeil in der oberen rechten Ecke drücken - es gibt drei generelle Ansätze, um Ausreißer auszuschließen:
basierend auf z-Scores (der absolute Wert sollte größer als 3,3 sein; dies entspricht einer Wahrscheinlichkeit von 0,1% = 1 / 1000; basierend auf einer Standardnormalverteilung ~ parametrisch)
basierend auf dem IQR (wie in einem Boxplot; basierend auf Rängen und Quantilen ~ nicht-parametrisch)
auf der Grundlage der Mahalanobis-Distanz (multivariate Ausreißer)
für 1. und 2. gibt es Funktionen in jamovi (siehe die nächsten Aufzählungspunkte), für 3. muss manR-Code verwenden (zwei Aufzählungspunkte weiter unten beschrieben); für 2. kann man es auch visuell machen (drei Aufzählungspunkte weiter unten) - Sie können entweder eine funktionsbasierte Auswahl verwenden; die nachstehenden Funktionen filtern Zeilen entweder auf der Grundlage der z-Scores (erste Zeile), des Interquartilsbereichs (IQR, zweite Zeile) oder durch Ausschluss bestimmter Zeilen/Zeilennummern (z. B. auf der Grundlage der Ergebnisse der Berechnung des Mahalanobis-Abstands weiter unten; dritte Zeile):
MAXABSZ([VARIABLE1], [VARIABLE2], …)
MAXABSIQR([VARIABLE1], [VARIABLE2], …)
IFMISS(MATCH(ROW(), [ROWNUMBER 1], [ROWNUMBER 2], …), 1, 0)
 das folgende Codebeispiel erkennt multivariate Ausreißer auf der Grundlage der Mahalanobis-Distanz (denken Sie daran, die Variablennamen in VL anzupassen)
das folgende Codebeispiel erkennt multivariate Ausreißer auf der Grundlage der Mahalanobis-Distanz (denken Sie daran, die Variablennamen in VL anzupassen)# this list should contain the names of your INDEPENDENT VARIABLES # you should not include your dependent variables # if you already use a filter set it to inactive # hint: you can get the names of your variable with names(data) # the syntax is adjusted for jamovi (the data frame is called data, # but can easily be used within R by just changing data to the name of your data frame VL = c('dan.sleep', 'baby.sleep', 'day') # brief explanation: the code calculates the Mahalanobis distance for all variables in VL, # then calculates the p-value (pchisq) and show lines with variables that had a p-value < 0.001 row.names(data)[ pchisq(unname( mahalanobis(data[, VL], colMeans(data[, VL]), cov(data[, VL]))), df=length(VL), lower.tail=FALSE) < 0.001]
die Ausgabe desR-Codes sagt Ihnen, welche Zeilen Sie herausfiltern solltenSie verwenden die Skripte im Rj-Editor, kopieren Sie sie einfach und fügen Sie sie ein und führen Sie sie aus, indem Sie auf die ►-Taste drücken (das kleine grüne Dreieck) - die Filterbedingungen können dann mit booleschen
and/orkombiniert werden:MAXABSZ([VARIABLE1], [VARIABLE2], …) < 3.3 and MAXABSIQR([VARIABLE1], [VARIABLE2], …) < 3 and IFMISS(MATCH(ROW(), [ROWNUMBER 1], [ROWNUMBER 2], …), 1, 0)
- anstelle der zweiten Zeile (
MAXABSIQR) könnten Sie auch Fälle herausfiltern, indem Sie die entsprechenden Zeilennummern im Datensatz ausschließen (wie in der dritten Zeile; Sie würden dann die Ausreißer in den Box-Plots unterDescriptivesvisuell überprüfen und sicherstellen, dass das KontrollkästchenLabel outliersgesetzt ist und die Zeilennummern, die als Ausreißer markiert sind, ausschließen)