Autor des Abschnitts: Jonathon Love
Die Datentabelle
In jamovi werden die Daten in einer Tabelle dargestellt, in der jede Spalte eine „Variable“ darstellt.
Datenvariablen
Die am häufigsten verwendeten Variablen in jamovi sind „Datenvariablen“. Diese Variablen enthalten Daten, die entweder aus einer Datendatei geladen oder vom Benutzer „eingetippt“ wurden. Datenvariablen können einer der drei folgenden Datentypen sein:
Integer
Decimal
Textund eines von vier Skalenniveaus:

Nominal

Ordinal

Continuous

IDDie Skalenniveaus werden durch das Symbol in der Kopfzeile der Variablenspalte angezeigt. Beachten Sie, dass einige Kombinationen von Datentyp und Skalenniveau nicht als Kombination auftreten können / sollten und das jamovi Sie solche Kombinationen nicht wählen lässt.
NominalundOrdinalkennzeichnen nominale und ordinale Variablen.Continuousist für Variablen mit numerischen Werten, die als Intervall- oder Ratio-Skalen betrachtet werden (äquivalent zuScalein SPSS). Der SkalentypIDexistiert nur in jamovi. Er ist für Variablen gedacht, die Identifikatoren enthalten, die man nie analysieren möchte (z.B. Name oder ID eines Versuchsteilnehmers). Der Vorteil von IDs ist, dass jamovi intern keine Liste von Faktorstufen im Speicher halten muss (R repräsentiert Text-Variablen intern oft als Faktoren), was die Leistung bei der Interaktion mit sehr großen Datensätzen verbessern kann.Wenn Sie mit einer leeren Datentabelle beginnen und Werte eingeben, ändern sich Datentypen und Skalenniveaus automatisch in Abhängigkeit von den eingegebenen Daten. Dies ist eine gute Möglichkeit, ein Gefühl dafür zu bekommen, welche Variablentypen zu welcher Art von Daten passen. In ähnlicher Weise versucht jamovi beim Öffnen einer Datendatei den am besten passenden Variablentyp aus den Daten in jeder Spalte abzuleiten. In beiden Fällen kann es sein, dass diese automatische Bestimmung nicht korrekt ist. Daher kann es notwendig werden, den Datentyp und das Skalenniveau im Nachhinein manuell anzupassen.
Der Variablen-Editor kann durch Auswahl von
Setupauf der RegisterkarteDaten, durch Doppelklick auf die Spaltenüberschrift der betreffenden Variable oder durch das Drücken vonF3aufgerufen werden. Im Variablen-Editor können Sie den Namen der Variable und (bei Datenvariablen) den Datentyp, das Skalenniveau, die Stufen eines Faktors und das Label / die Bezeichnung für die unterschiedlichen Faktorstufen ändern. Der Variablen-Editor kann durch Anklicken des Schließpfeils oder durch erneutes Drücken der TasteF3verlassen werden.Neue Variablen können mit der Schaltfläche
Hinzufügenaus der RegisterkarteDatenin den Datensatz eingefügt (vor der aktuellen Cursor-Position) oder angehängt werden (am Ende der existierenden Variablen). Die SchaltflächeHinzufügenermöglicht auch das Hinzufügen von Berechneten Variablen.
Berechnete Variablen
Berechnete Variablen sind solche, die ihren Wert durch die Durchführung einer Berechnung basiert auf einer oder mehreren anderen Variablen erhalten. Berechnete Variablen können für eine Reihe von Zwecken verwendet werden, z. B. für logarithmische Transformationen, z-Transformationen, das Berechnen von Skalenwerten (Summe oder Mittelwert), für die Inversion von Skalenitems, etc.
Berechnete Variablen können dem Datensatz mit der Schaltfläche
Hinzufügen, die unter der RegisterkarteDatenverfügbar ist, hinzugefügt werden. Dabei wird ein Formel-Feld angezeigt, in dem Sie die Formel angeben oder zusammenklicken (fx-Button) können. Es stehen die üblichen arithmetischen Operatoren zur Verfügung. Einige Beispiele für Formeln sind:A + B LOG10(len) MEAN(A, B) (dose - VMEAN(dose)) / VSTDEV(dose) Z(dose)In dieser Reihenfolge sind das die Summe von A und B, eine logarithmische Transformation (zur Basis 10) von
len, der Mittelwert vonAundB, und der z-Score vondose(mit zwei unterschiedlichen Berechnungsmethoden).Darüber hinaus sind viele weitere Funktionen verfügbar.
V-Funktionen
Von einer Reihe von Funktionen gibt es Paare, wobei dem einen Teil des Paares ein
Vvorangestellt ist und dem anderen nicht.V-Funktionen führen ihre Berechnung auf einer Variablen als Ganzes durch (spaltenweise), während Funktionen ohneVihre Berechnung zeilenweise durchführen. Zum Beispiel wirdMEAN(A, B)den Mittelwert vonAundBfür jede Zeile erzeugen. WährendVMEAN(A)den Mittelwert von allen Werten der VariableAliefert.Zusätzlich unterstützen
V-Funktionen eingroup_by-Argument. Wenn einegroup_by-Variable angegeben wird, dann wird für jede Ebene dergroup_by-Variable ein separater Wert berechnet. Im folgenden Beispiel:VMEAN(len, group_by=dose)Mit dieser Funktion wird ein separater Mittelwert für jede Stufe von
doseberechnet, und jeder Wert in der berechneten Variable ist der Mittelwert, der dem Wert vondosein der jeweiligen Zeile entspricht.
Transformierte (umkodierte) Variablen
Während sich berechnete Variablen für viele Operationen eignen (z. B. Berechnung von Summenwerten, Generierung von Daten usw.), kann es etwas mühsam sein, wenn Sie mehrere Variablen neu kodieren oder transformieren möchten (z. B. beim Invertieren von Items in einem Umfragedatensatz). Mit „transformierten Variablen“ können Sie vorhandene Variablen einfach umkodieren und Transformationen auf viele Variablen gleichzeitig anwenden.
Erstellen von transformierten Variablen
Beim Transformieren oder Umkodieren von Variablen in jamovi wird eine „transformierte Variable“ für die ursprüngliche „Quellvariable“ erstellt. Auf diese Weise haben Sie bei Bedarf immer Zugriff auf die ursprünglichen, untransformierten Daten. Um eine Variable zu transformieren, wählen Sie zunächst die Variable(n) aus, die Sie transformieren möchten. Sie können einen Block mit mehreren Variablen auswählen, indem Sie auf die Kopfzeile / Überschrift der ersten Variable des Blocks klicken und dann bei gedrückter ⇧-Taste auf die letzte Überschrift der letzten Variable im Block klicken. Alternativ können Sie einzelne Spalten auswählen bzw. die Auswahl aufheben, indem Sie bei gedrückter Strg- bzw. Befehlstaste auf die Spaltenüberschriften klicken. Nach der Auswahl können Sie entweder
Transformierenin der RegisterkarteDatenauswählen oder mit der rechten Maustaste klicken undTransformierenaus dem Menü wählen.Klicken Sie entweder mit der rechten Maustaste auf eine der ausgewählten Variablen, und klicken Sie auf
Transformieren...:
oder gehen Sie zur Registerkarte
Datenund klicken Sie aufTransformieren
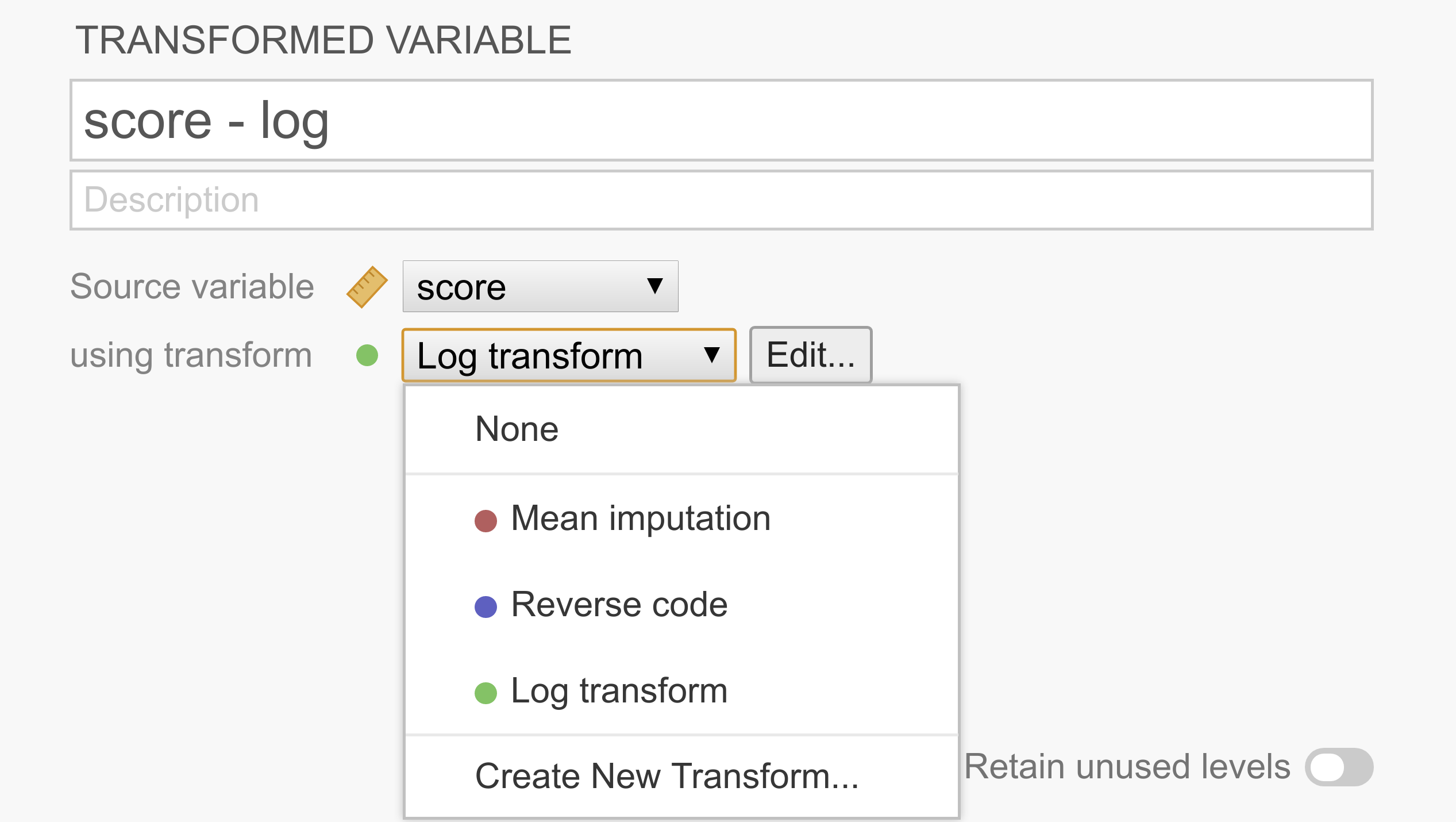
Dadurch wird für jede ausgewählte Spalte eine zweite „transformierte Variable“ erstellt. Im folgenden Beispiel wurde nur eine einzige Variable ausgewählt, so dass wir die Transformation nur für eine Variable (mit dem Namen score - log) einrichten, aber es gibt keinen Grund, warum wir nicht mehrere Variablen in einem Durchgang transformieren können.
Wie in der obigen Abbildung zu sehen ist, hat jede transformierte Variable eine „Quellvariable“, welche die ursprüngliche, nicht transformierte Variable repräsentiert, und eine Transformation, welche die Regeln zur Umwandlung der Quellvariable in die transformierte Variable enthält. Nachdem eine Transformation erstellt wurde, steht sie in der Liste zur Verfügung und kann problemlos wiederverwendet werden, um andere Variablen zu transformieren.
Wenn Sie die entsprechende Transformation noch nicht definiert haben, können Sie
Neue Transformation erstellen...aus der Liste auswählen.Eine neue Transformation erstellen
Durch einen Klick auf
Neue Transformation erstellen...wird der Transformationseditor eingeblendet:
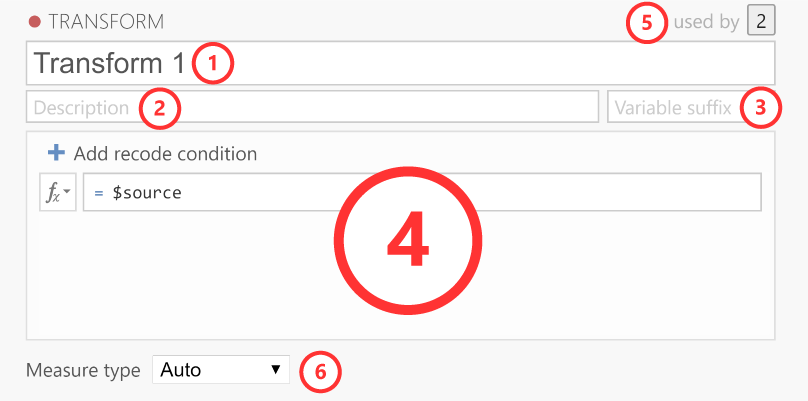
Der Transformationseditor enthält diese Elemente.
Name: Der Name für die Transformation.
Beschreibung: Hier können Sie eine Beschreibung der Transformation angeben, damit Sie (und andere) wissen, was sie bewirkt.
Variablensuffix (optional): Hier können Sie die Standard-Namensformatierung für die transformierte Variable festlegen. Standardmäßig wird das Variablensuffix an den Namen der Quellvariablen angehängt, mit einem Bindestrich (-) dazwischen. Sie können dieses Verhalten jedoch außer Kraft setzen, indem Sie drei Punkte (…) verwenden, die dann durch den Variablennamen ersetzt werden. Wenn Sie beispielsweise eine Variable mit dem Namen Q1 transformieren, können Sie Variablensuffixe verwenden, um die folgenden Benennungsschemata anzuwenden (wenn Sie nichts eingeben, wird der Transformationsname als Variablensuffix verwendet):
log→Q1 - log..._log→Q1_loglog(...)→log(Q1)Transformation: Dieser Abschnitt enthält die Regeln und Formeln für die Transformation. Sie können alle Funktionen verwenden, die für berechnete Variablen zur Verfügung stehen. Um auf die Werte in der Ausgangsspalte zu verweisen (damit Sie diese umwandeln können), können Sie das spezielle Schlüsselwort
$sourceverwenden. Wenn Sie eine Variable in mehrere Gruppen umkodieren wollen, ist es am einfachsten, mehrere Bedingungen zu verwenden. Um zusätzliche Bedingungen (d. h. Wenn-Anweisungen) hinzuzufügen, klicken Sie auf die SchaltflächeUmkodierungsbedingung hinzufügen:Verwendet von: Zeigt an, wie viele Variablen diese bestimmte Transformation verwenden. Wenn Sie auf die Zahl klicken, werden diese Variablen aufgelistet.
Skalenniveau: Standardmäßig ist das Skalenniveau auf „Auto“ eingestellt, wodurch das Skalenniveau automatisch aus der Transformation abgeleitet wird. Wenn „Auto“ das Skalenniveau jedoch nicht korrekt herleitet, können Sie es hier überschreiben.
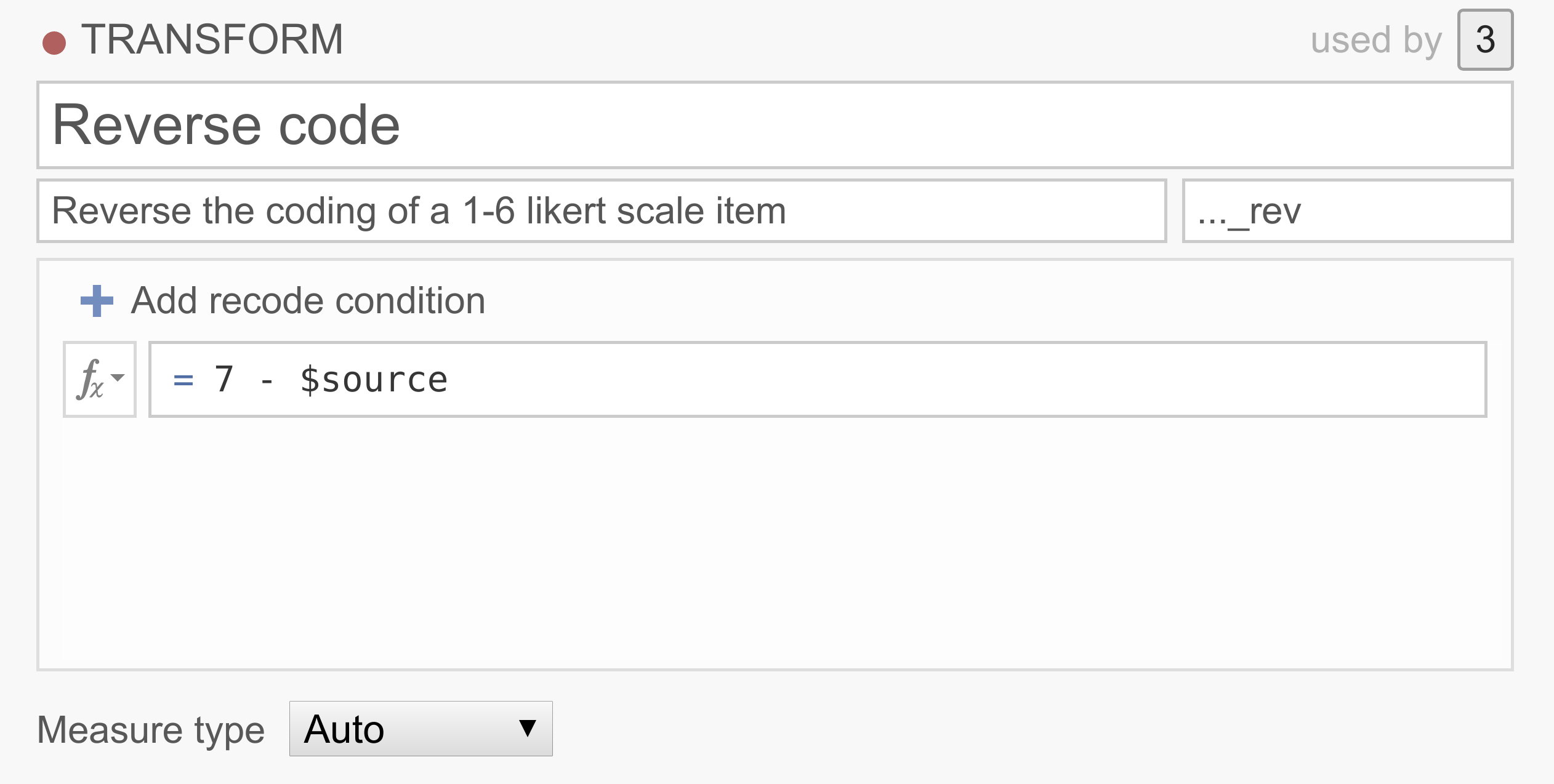
Beispiel 1: Invertieren von Items
Umfragedaten enthalten oft ein oder mehrere Items, deren Werte vor der Analyse invertiert werden müssen. Zum Beispiel könnten wir die Extravertiertheit mit den Fragen „Ich gehe gerne auf Partys“, „Ich bin gerne unter Menschen“ und „Ich bleibe lieber für mich“ messen. Eine Person, die auf die letzte Frage mit 6 (stimme voll und ganz zu) antwortet, sollte nicht als extravertiert angesehen werden, und daher sollte 6 als 1, 5 als 2, 1 als 6 usw. behandelt werden. Um solche Items zu invertieren, können wir die folgende einfache Transformation verwenden:
Sie können diese Transformation selbst ausprobieren, indem Sie
um_transform_ex1.omvherunterladen und in jamovi öffnen.Beispiel 2: Umkodieren kontinuierlicher Variablen in Kategorien
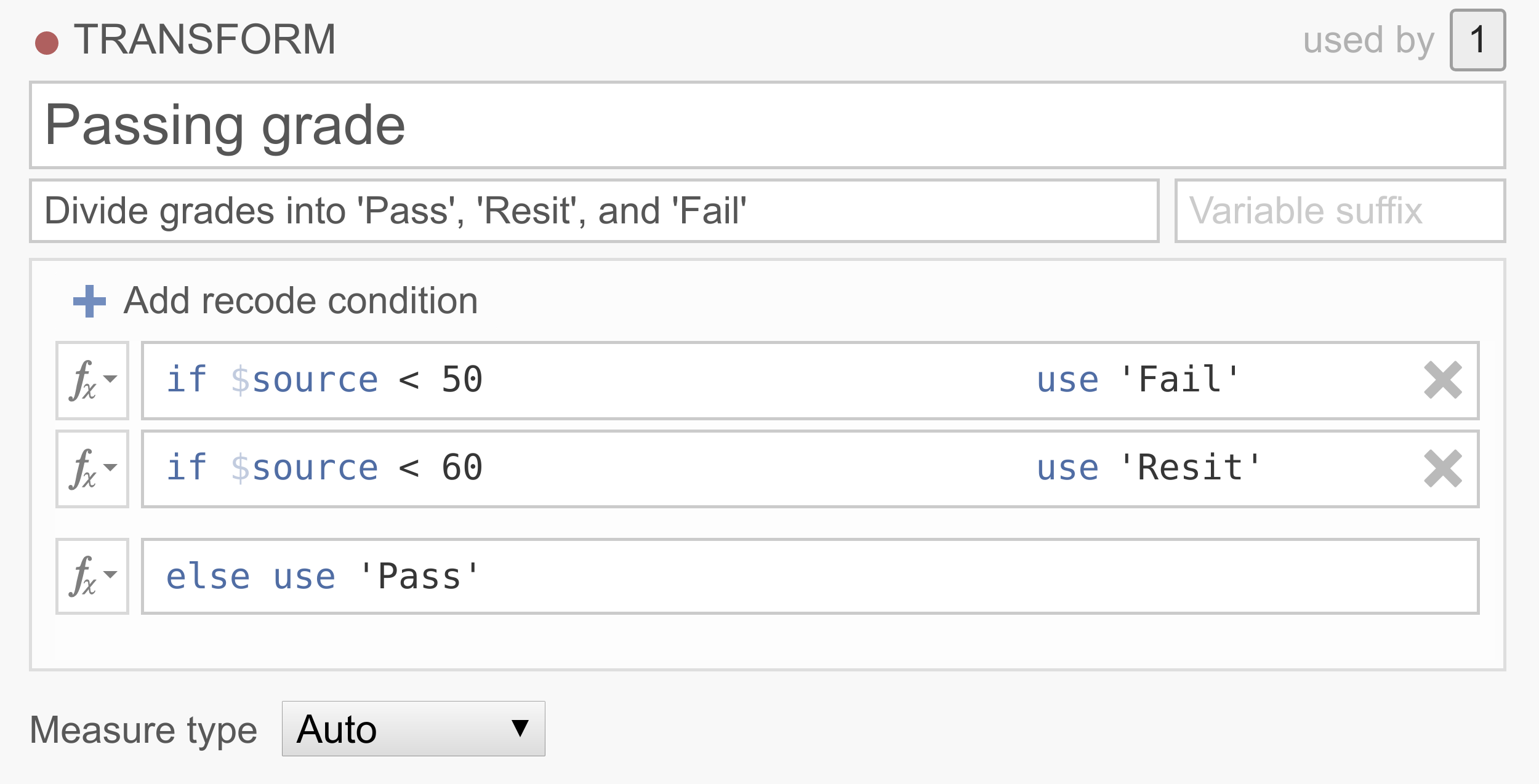
In vielen Datensätzen möchte man kontinuierliche Daten in Kategorien umkodieren. Zum Beispiel können wir Personen auf der Grundlage ihrer Testergebnisse (0 bis 100%) in eine von drei Gruppen
Pass,ResitundFaileinteilen.
Beachten Sie, dass die Bedingungen der Reihe nach ausgeführt werden und dass nur die erste Regel, die auf einen Fall zutrifft, angewendet wird. Diese Transformation besagt also im Wesentlichen, dass, wenn die Originalvariable einen Wert unter 50 hat, der Wert
Failsein wird, wenn die Quellvariable einen Wert zwischen 50 und 60 hat, der WertResitsein wird, und wenn die Quellvariable einen Wert über 60 hat, der WertPasssein wird. Wenn Sie einen Beispieldatensatz zum Ausprobieren haben möchten, können Sieum_transform_ex2.omvherunterladen und verwenden.Beispiel 3: Ersetzen fehlender Werte
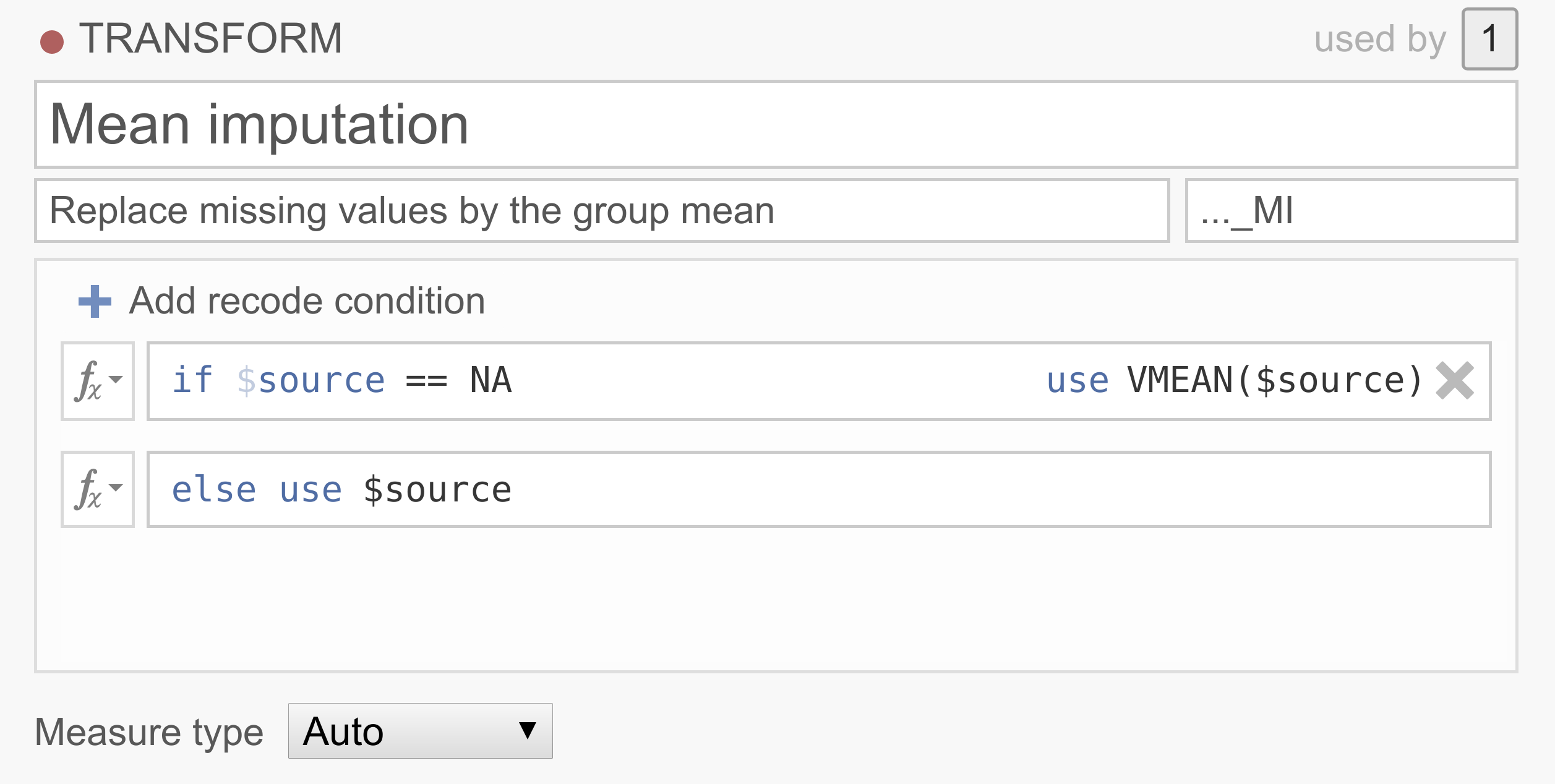
Angenommen, Ihr Datensatz enthält viele fehlende Werte, und das Entfernen der Teilnehmer mit fehlenden Werten würde zu einem erheblichen Verlust an Teilnehmern führen. Es gibt eine Reihe von Möglichkeiten, mit fehlenden Werten umzugehen, wobei oft Imputation verwendet wird. Eine unkomplizierte Imputationsmethode ersetzt die fehlenden Werte durch den Mittelwert der Variablen (d. h. Mittelwertsubstitution). Obwohl es eine Reihe von Problemen im Zusammenhang mit der Mittelwertsubstitution gibt und man sie deswegen eher nicht benutzen sollte, eignet sie sich gut zur Demonstration…
Beachten Sie, dass jamovi
NAvon R übernommen hat, um fehlende Werte zu kennzeichnen. Sie haben keinen guten Datensatz zur Hand? Sie können es selbst ausprobieren, indem Sieum_transform_ex3.omvherunterladen und öffnen.
Filter
Mit Filtern können Sie in jamovi Zeilen herausfiltern, die Sie aus Ihrer Analyse ausschließen wollen. Zum Beispiel können Sie die Umfrageantworten von Personen nur dann einbeziehen, wenn diese ausdrücklich der Verwendung ihrer Daten zugestimmt haben, Sie könnten alle Linkshänder ausschließen, oder Personen, die bei einer experimentellen Aufgabe „unter Zufallsniveau“ abschneiden. Filter eignen sich auch, um extreme Werte auszuschließen, zum Beispiel solche, die mehr als 3 Standardabweichungen vom Mittelwert abweichen oder die Extremwerte in Bezug auf ihren Interquartilbereich sind (IQR; d.h. Extremwerte außerhalb der Whisker im Box-Whisker-Diagramm).
Die Filter in jamovi bauen auf dem jamovis‘ Formelsystem für Berechnete Variablen auf. Dies ermöglicht das Erstellen (und Filtern) beliebig komplexer Formeln.
Zeilenfilter
jamovi-Filter lassen sich anhand des
Tooth Growth-Datensatzes demonstrieren, der in jamovi enthalten ist (☰→Open→Data Library). Wählen Sie dasFilter-Icon aus der RegisterkarteDaten. Dies öffnet die Filteransicht und erstellt einen neuen Filter namensFilter 1.In dem kurzen Video verwenden wir einen Filter, um die 9. Zeile auszuschließen. Vielleicht wissen wir, dass der 9. Teilnehmer jemand war, der nur das Umfragesystem getestet hat, und kein richtiger Teilnehmer (
Tooth Growthist ein Datensatz der die Länge von Meerschweinchenzähnen untersucht, also wissen wir vielleicht, dass der 9. Teilnehmer ein Kaninchen war). Wir können sie einfach mit der folgenden Formel ausschließen:ROW() != 9In diesem Ausdruck bedeutet das
!=„nicht gleich“. Wenn Sie jemals eine Programmiersprache wie R verwendet haben, sollte Ihnen das vertraut sein. Filter in jamovi schließen die Zeilen aus, für welche die Formel nicht wahr ist. In diesem Fall ist der AusdruckROW() != 9für alle Zeilen wahr, außer für die 9. Wenn wir diesen Filter anwenden, wird das Häkchen in der SpalteFilter 1der 9. Zeile zu einem Kreuz und die gesamte Zeile wird grau. Wenn wir jetzt eine Analyse durchführen würden, würde sie so ablaufen, als ob die 9. Zeile nicht vorhanden wäre. Ähnlich verhält es sich, wenn wir bereits einige Analysen durchgeführt haben: Sie werden erneut ausgeführt und die Ergebnisse werden auf Werte aktualisiert, die sich ergäben würden, wenn die 9. Zeile nicht verwendet würde.Normalerweise hätten wir gerne komplexere Filter als diese! Das Beispiel
Tooth Growthenthält die Länge der Zähne von Meerschweinchen (in der Spaltelen), die mit verschiedenen Dosierungen (Spaltedose) von Nahrungsergänzungsmitteln gefüttert wurden: Vitamin C oder Orangensaft (aufgezeichnet in der SpaltesuppalsVCundOJ). Nehmen wir an, dass wir an der Wirkung der Dosierung auf die Zahnlänge interessiert sind. Wir könnten eine ANOVA mitlenals abhängige Variable unddoseals gruppierende Variable durchführen. Aber nehmen wir an, dass wir nur an den Auswirkungen von Vitamin C interessiert sind und nicht an denen von Orangensaft. Dann können wir die folgende Formel verwenden:supp == 'VC'Wir können diese Formel sogar zusätzlich zur Formel
ROW() != 9verwenden, wenn wir wollen. Wir können sie als weiteren Ausdruck zuFilter 1hinzufügen (indem wir auf das kleine+neben der ersten Formel klicken), oder wir können sie als zusätzlichen Filter hinzufügen (indem wir das große+auf der linken Seite des Filter-Dialogfelds auswählen). Wie wir sehen werden, bietet das Hinzufügen eines Ausdrucks zu einem bestehenden Filter nicht genau dasselbe Verhalten wie das Erstellen eines separaten Filters. In diesem Fall macht es jedoch keinen Unterschied, also fügen wir ihn einfach dem vorhandenen Filter hinzu. Dieser zusätzliche Ausdruck wird ebenfalls in einer eigenen Spalte dargestellt, und anhand der Häkchen und Kreuze können wir sehen, welcher Filter oder Ausdruck für den Ausschluss jeder Zeile verantwortlich ist.Aber nehmen wir an, wir wollen alle Zahnlängen, die mehr als 1,5 Standardabweichungen vom Mittelwert abweichen, aus der Analyse ausschließen. Dazu nehmen wir eine z-Standardisierung vor und prüfen, ob der z-Wert zwischen -1,5 und 1,5 liegt. Wir könnten eine der folgenden Formeln verwenden (diese zweite Formel eignet sich hervorragend, um den Studenten zu zeigen, was ein z-Wert ist):
-1.5 < Z(len) < 1.5 -1.5 < (len - VMEAN(len)) / VSTDEV(len) < 1.5In jamovi stehen viele Funktionen zur Verfügung. Sie können sie sehen, wenn Sie auf das kleine fx neben dem Formel-Eingabefeld klicken.
Fügen wir nun diese Formel zur z-Standardisierung als einen separaten Filter hinzu. Dazu klicken wir auf das große
+links neben den Filtern und fügren die Formel zuFilter 2hinzu.Bei mehreren Filtern werden die gefilterten Zeilen kaskadenartig von einem Filter in den nächsten übertragen. So werden nur die Zeilen, die von
Filter 1durchgelassen wurden, in den Berechnungen fürFilter 2verwendet. In diesem Fall basieren der Mittelwert und die Standardabweichung für den z-Score nur auf den Vitamin-C-Zeilen (und auch nicht auf Zeile 9). Hätten wir dagegen unseren FilterZ()als zusätzlichen Ausdruck inFilter 1angegeben, dann würden der Mittelwert und die Standardabweichung für den z-Score auf dem gesamten Datensatz basieren. Auf diese Weise können Sie beliebig komplexe Regeln dafür festlegen, wann eine Zeile in die Analysen einbezogen werden soll oder nicht (Sie sollten Ihre Regeln jedoch im prå-registrieren).[1]Variablenfilter
Während Zeilenfilter auf den Datensatz als Ganzes angewendet werden, möchten Sie manchmal nur einzelne Spalten filtern. Spaltenfilter sind nützlich, wenn Sie einige Zeilen für bestimmte Analysen auswählen wollen, aber nicht für alle. Dies wird durch berechnete Variablen erreicht. Mit einer solchen berechneten Variablen erstellen wir eine Kopie einer vorhandenen Spalte, wo nur die erwünschten (zu analysierenden) Werte eingeschlossen werden.
Im Beispiel des
Tooth Growth-Datensatzes möchten wir vielleicht die verschiedenen Dosierungen 500 und 1000 sowie 1000 und 2000 getrennt analysieren. Zu diesem Zweck erstellen wir eine neue Spalte für jede dieser Untergruppen. In unserem Beispiel können wir also die Spaltedoseim der jamovi-Datentabelle auswählen und dann in der RegisterkarteDatendie SchaltflächeBerechnenwählen. Dadurch wird rechts eine neue Spalte mit dem Namendose (2)erstellt, und wie bei den Filtern können wir eine Formel eingeben. In diesem Fall geben wir eine der folgenden Formeln ein (die beiden sind gleich, die zweite ist vielleicht einfacher zu verstehen):FILTER(dose, dose <= 1000) FILTER(dose, dose == 1000 or dose == 500)Das erste Argument der Funktion
FILTER()(in diesem Beispiel Dosis) gibt an, welche Werte in der berechneten Spalte verwendet werden sollen. Das zweite Argument ist die Bedingung; wenn diese Bedingung nicht erfüllt ist, wird der Wert leer angezeigt (oder als „fehlender Wert“, wenn Sie das vorziehen). Mit dieser Formel enthält die Spaltedose (2)alle Werte von500und1000, während die Werte für2000ausgeschlossen wurden.Wir könnten auch den Namen der Spalte in etwas Beschreibenderes ändern, wie
dose 5,10. Auf ähnliche Weise können wir eine Spaltedose 10,20mit der FormelFILTER(dose, dose != 500)erstellen. Jetzt können wir zwei getrennte ANOVAs (oder t-Tests) durchführen, wobeilenals abhängige Variable unddose 5,10als eine gruppierende Variable in der ersten Analyse unddose 10,20in der anderen verwendet werden. Auf diese Weise können wir verschiedene Filter für verschiedene Analysen verwenden. Dies ist ein Unterschied zu Zeilenfiltern, die auf alle Analysen angewendet werden.Mit
FILTER()lassen sich daher Analysen aufteilen: Sie können mitFILTER()die dafür notwendigen Variablen erstellen. Zum Beispiel könnten wirlenmit den FunktionenFILTER(len, supp == 'VC')bzw.FILTER(len, supp == 'OJ')in zwei neue Spaltenlen_VCundlen_OJaufteilen. Dadurch entstehen zwei getrennte Spalten, die wir getrennt voneinander analysieren können.