Autor des Abschnitts: Rebecca Vederhus, Sebastian Jentschke
Von SPSS zu jamovi: Kovarianzanalyse (ANCOVA)¶
Dieser Vergleich zeigt, wie eine Regression mit einem Prädiktor und zwei Dummy-Variablen in SPSS und jamovi durchgeführt wird. Der SPSS-Test folgt der Beschreibung in Kapitel 13.3 von Field (2017), und fokussiert insbesondere auf Output 13.1 - 13.2. Die Analyse verwendet den Datensatz Puppy Love Dummy.sav, der von der Webseite zum Buch heruntergeladen werden kann.
| SPSS | jamovi |
|---|---|
In SPSS können Sie eine Regression durchführen mit: Analyze → Regression → Linear. |
In jamovi tun Sie dies mit: Analyses → Regression → Linear Regression. |
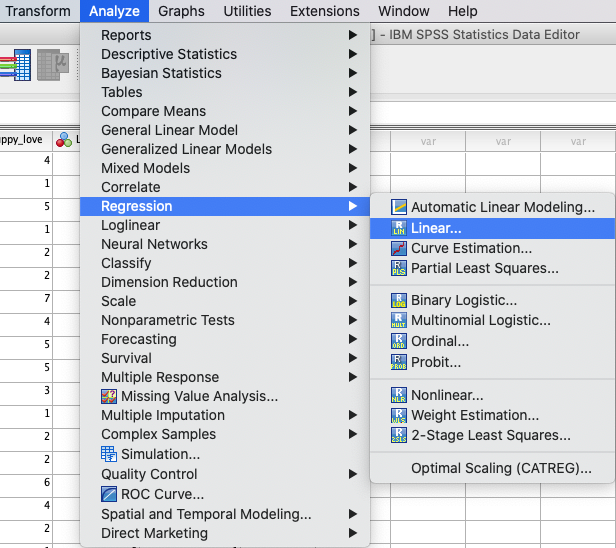 |
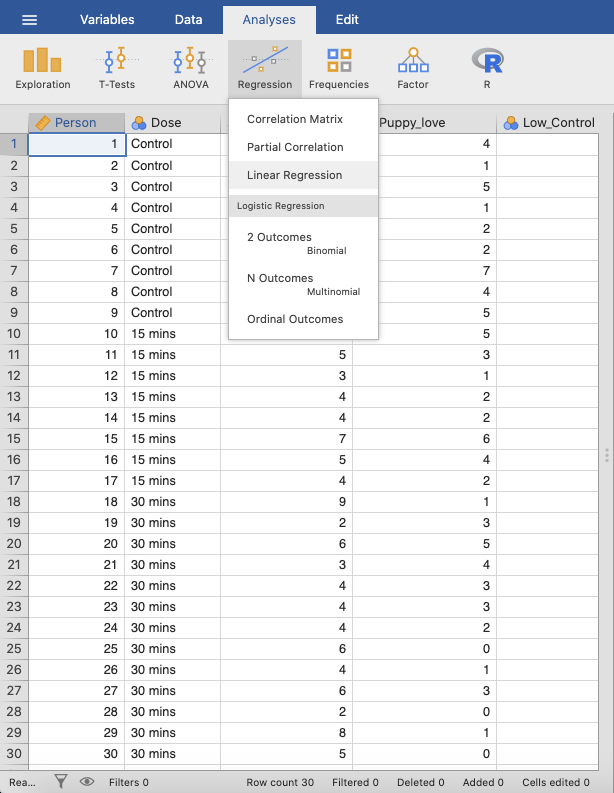 |
In SPSS, verschieben Sie Happiness in das Variablenfeld Dependent und Puppy_love in das Variablenfeld Independent(s). |
In jamovi verschieben Sie Happiness in das Variablenfeld Dependent Variable, Puppy_love in das Variablenfeld Covariates, und Low_Control und High_Control in das Feld Factors. |
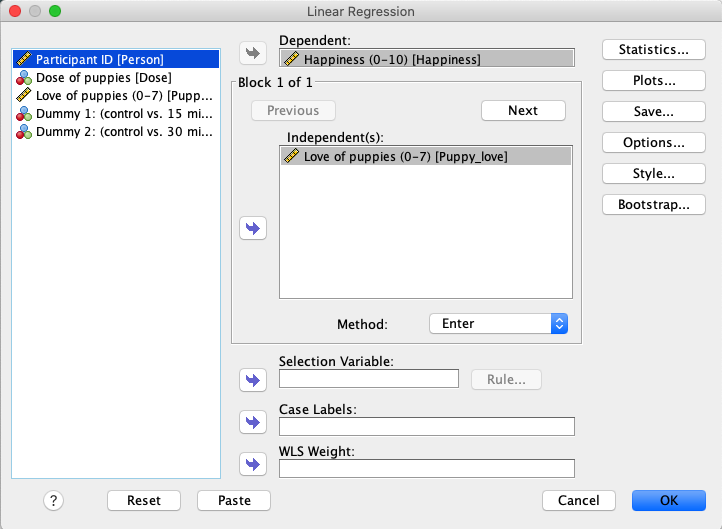 |
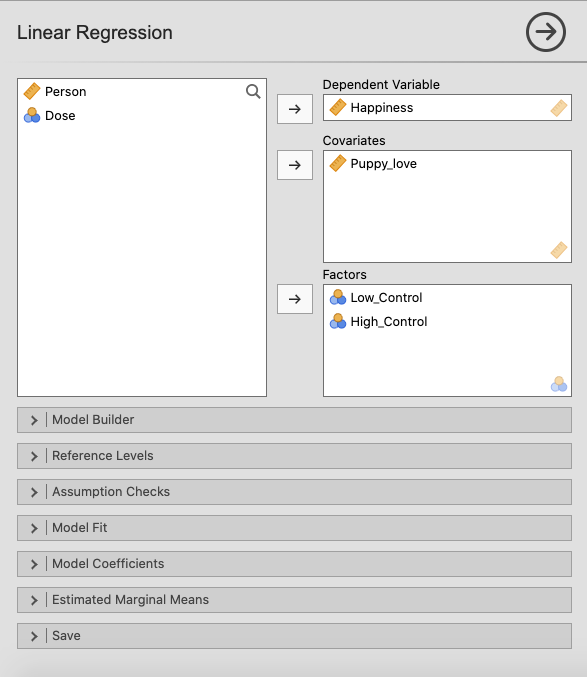 |
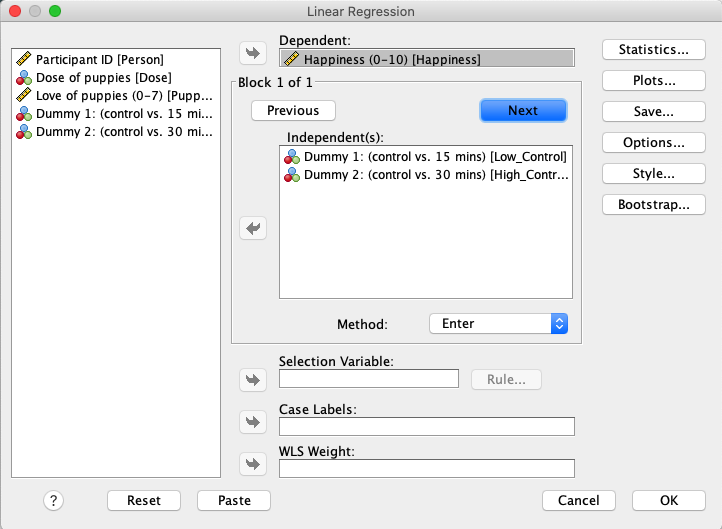
Drücken Sie die Taste Next, um einen neuen Block von Independent(s) zu erstellen, und verschieben Sie die Variablen Low_Control und High_Control in dieses Feld. |
Erstellen Sie mit Model Builder einen neuen Block mit unabhängigen Variablen. Drücken Sie + Add New Block und verschieben Sie Low_Control und High_Control nach Block 2. |
 |
 |
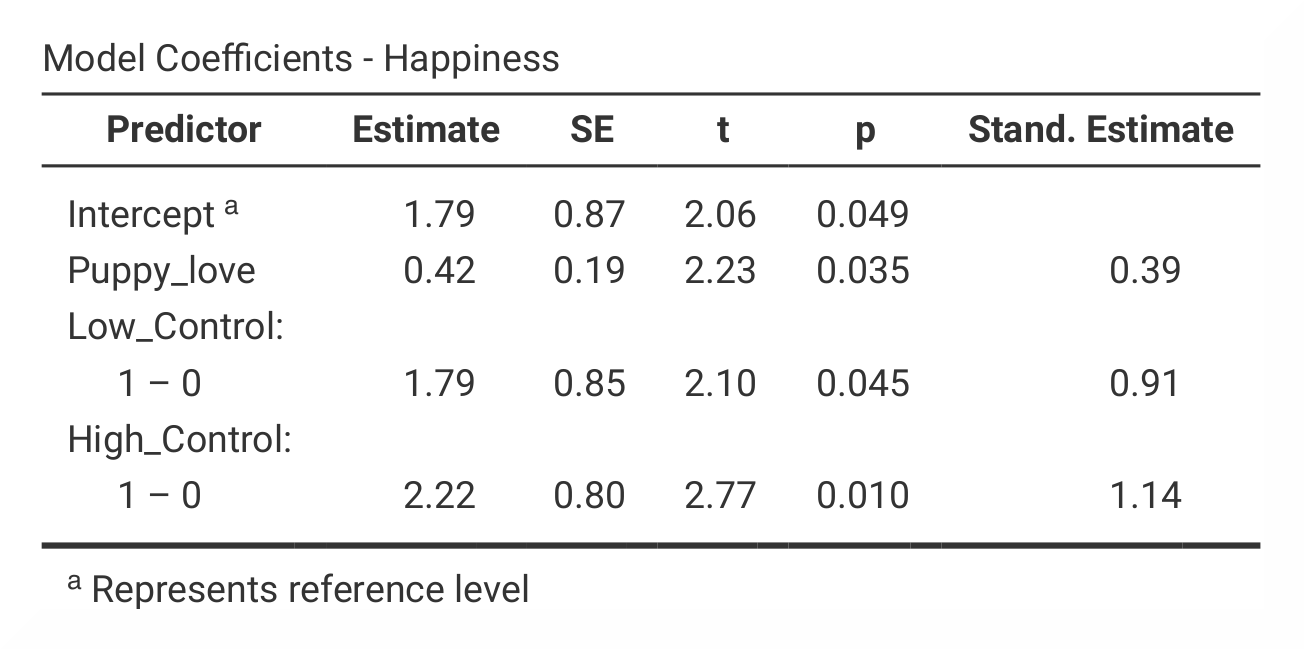
Öffnen Sie das Fenster Model Coefficients und markieren Sie das Kästchen für Standardized estimate. |
|
 |
|
| Wenn Sie die Ausgaben von SPSS und jamovi vergleichen, sind die Ergebnisse gleich. Allerdings ist die Ausgabe von jamovi viel übersichtlicher, da sie nur die wichtigsten Informationen enthält. Die Ergebnisse sind in SPSS und jamovi an leicht unterschiedlichen Stellen zu finden. | |
|
|
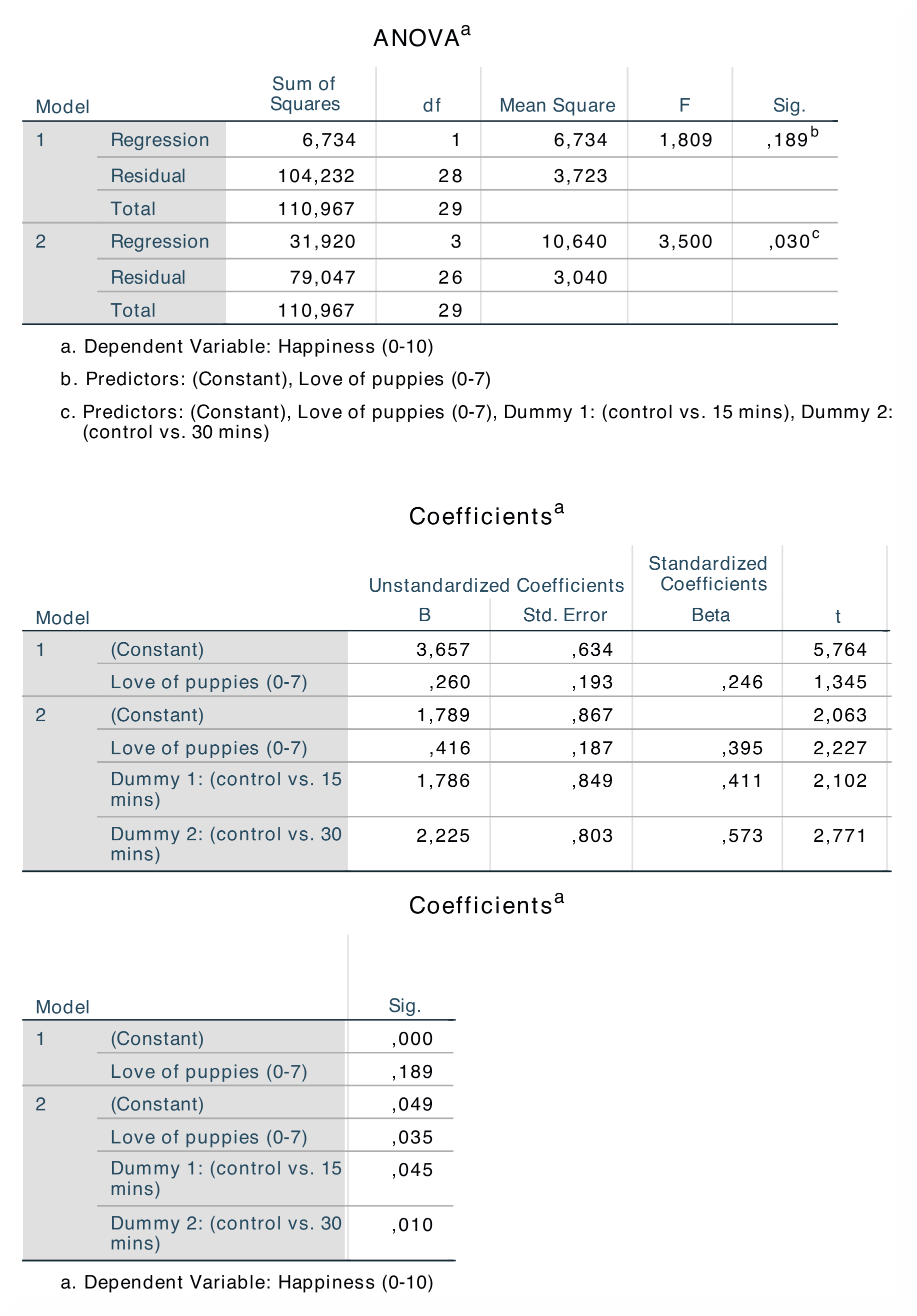
In SPSS beginnt die Ausgabetabelle Model Summary mit R und R². Der R²-Wert für Modell 1 zeigt die Anpassungsgüte, wenn nur die Kovariate in die Analyse einbezogen wird, und der Wert für Modell 2 zeigt die Ergebnisse, wenn die Dummy-Variablen und die Kovariate einbezogen werden. Die Tabelle ANOVA zeigt die Quadratsumme für die Regression, die uns sagt, wie viele Varianzeinheiten das Modell berücksichtigt. Die interessanteste Tabelle ist die Tabelle Coefficients, in der die Unterschiede in den b-Werten und β-Werten für die beiden Modelle sowie deren Signifikanzwerte aufgeführt sind. |
In jamovi finden sich die R *- und *R²-Werte in der Ausgabetabelle Model Fit Measures. Die Quadratsumme und die F-Werte finden sich in der Tabelle Omnibus ANOVA Test, die in jamovi in eine Tabelle für Modell 1 und eine Tabelle für Modell 2 unterteilt ist, wobei die Zahlen an der gleichen Stelle in den Tabellen erscheinen. Die Tabelle Coefficients ist in jamovi ebenfalls in zwei Tabellen – eine für jedes Modell – unterteilt. Hier finden sich die b-Werte unter Estimate und die β-Werte unter Stand. Estimate. |
Die R *- und *R²-Werte finden sich sowohl in SPSS als auch in jamovi in der ersten und zweiten Spalte der ersten Ausgabetabelle. Im Gegensatz zu SPSS teilt jamovi die Die Statistiken für Modell 2 sind numerisch identisch: R = 0,54, R² = 0,29; b = 0.42, β = 0,39, p < .05. |
|
| If you wish to replicate those analyses using syntax, you can use the commands below (in jamovi, just copy to code below to Rj). Alternatively, you can download the SPSS output files and the jamovi files with the analyses from below the syntax. | |
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Happiness
/METHOD=ENTER Puppy_love
/METHOD=ENTER Low_Control High_Control.
|
jmv::linReg(
data = data,
dep = Happiness,
covs = Puppy_love,
factors = vars(Low_Control, High_Control),
blocks = list(
list("Puppy_love"),
list("Low_Control", "High_Control")),
refLevels = list(
list(var="Low_Control", ref="0"),
list(var="High_Control", ref="0")),
anova = TRUE)
|
| SPSS-Ausgabedatei mit den Analysen | jamovi-Datei mit den Analysen |


Referenzen
Field, A. (2017). Discovering statistics using IBM SPSS statistics (5th ed.). SAGE Publications. https://edge.sagepub.com/field5e